CNN&RNN
LSTM & CNN 조합으로 영화리뷰 분류하기
DATA = IMDB(영화 관련 정보, 출연진, 개봉, 후기, 평점 등 영화 데이터 25,000여개 저장)
1. 라이브러리 설정
# 라이브러리 설정하기
from tensorflow.keras.preprocessing import sequence
from tensorflow.keras.models import Sequential
from tensorflow.keras.datasets import imdb
from tensorflow.keras.layers import Dense, Dropout, Activation
from tensorflow.keras.layers import Embedding
from tensorflow.keras.layers import Conv1D, MaxPooling1D
from tensorflow.keras.layers import LSTM
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as pltfrom keras import ~~ : 현재 keras 패키지에서 import할 module(ex. sequence, Sequential, imdb 등)
tensorflow, numpy, matplotlib 라이브러리 설정
2. 시드 값 고정하기
# seed 값 고정하기
seed = 0
np.random.seed(seed)
tf.set_random_seed(seed)seed = 0
numpy, tensorflow seed 값을 0으로 고정한다.
3. 데이터 가져오기 / trainset, testset 나누기
# num_words = 5000 -> 1~5000개의 단어만 가져올 것
# test_split : train 80%, test 20%
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=5000)imdb.load_data() : imdb 내장 데이터를 가져온다.
num_words = 5000은 1~5000개까지의 단어만 가져온다
(x_train, y_train), (x_test, y_test) = trainset, testset 나누기
4. 데이터 전처리
# pad_sequence(maxlen) = 단어 수를 100개로 맞춰라
# 단어 > 100 이라면 나머지 버림
# 단어 < 100 이라면 나머지 0으로 채움
x_train = sequence.pad_sequences(x_train, maxlen = 100)
x_test = sequence.pad_sequences(x_test, maxlen = 100)sequence.pad_sequences() : trainset, testset을 padding으로 길이 100까지 채워준다.
- 단어 > 100 이라면 나머지 버림
- 단어 < 100 이라면 나머지 0으로 채움
4. 딥러닝 모델 만들기
# 딥러닝 모델 설정
model = Sequential()
model.add(Embedding(5000,100))
model.add(Dropout(0.5))
model.add(Conv1D(64, 5, padding='same', activation='relu', strides=1))
model.add(MaxPooling1D(pool_size=4))
model.add(LSTM(55))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.summary()model = Sequential() : Sequential() 함수로 입력층 생성하기
model.add(Embedding(5000,100)) = Embedding('불러온 단어 총 개수', '기사당 단어 수')
: Embedding층은 데이터 전처리로 입력된 값을 다음층이 알아들을 수 있는 형태로 변환하는 역할.
model.add(Dropout(0.5)) : 네트워크의 유닛의 일부만 동작하고 일부는 동작하지 않도록 하는 방법
Dropout 0.5로 랜덤하게 노드를 꺼 과적합을 방지
model.add(Conv1D(64, 5, padding='same', activation='relu', strides=1))
- Conv1D(filters, kernel_size, activation, strides)
- Conv2D(filters, kernel_size, activation, strides)
- padding = 'same' or 'vaild'
▶ 'same' : 출력 이미지 사이즈 = 입력 이미지 사이즈 동일
▶ 'valid' : 유효한 영역만 출력함, 출력 이미지 사이즈 < 입 력이미지 사이즈
model.add(MaxPooling1D(pool_size=4)) : 1차원 데이터 최대값 풀링, 1/4로 크기 변경
- 1차원 데이터를 맥스풀링(최대값 풀링) 적용
- pool_size = 4 → 전체 크기의 1/4로 변경한다.
model.add(LSTM(55))
- LSTM() 값을 55로 받아서 SHAPE()해준다
summary() : Layer(type), 데이터 Output Shape, Param 보여주기

# 모델 컴파일
model.compile(loss ='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# 모델 실행
history = model.fit(x_train, y_train, epochs=5, batch_size = 100, validation_data=(x_test, y_test))model.compile(loss ='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
- 이진_교차 오차함수, 최적화 함수 : adam(모멘텀 최적화와 RMSProp의 아이디어를 합친 것)
history = model.fit(x_train, y_train, epochs=5, batch_size = 100, validation_data=(x_test, y_test))
- epochs 반복횟수 5번, batch_size 100번, 검증 데이터 =(x_test, y_test) 설정)
# 테스트 셋의 오차
y_vloss = history.history['val_loss']
# 학습셋의 오차
y_loss = history.history['loss']
# 그래프로 표현
x_len = np.arange(len(y_loss))
plt.plot(x_len, y_vloss, marker='.', c="red", label='Testset_loss')
plt.plot(x_len, y_loss, marker='.', c="blue", label='Trainset_loss')
# 그래프에 그리드를 주고 레이블을 표시
plt.legend(loc='upper right')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()테스트셋 오차 = 검증데이터 history['val_loss']
학습 오차 = 학습데이터 history['loss']
그래프로 표현하기
x_len = np.arange(len(y_loss)) : x_len = 학습셋 오차의 길이
plt.plot(x_len, y_vloss, marker='.', c="red", label='Testset_loss')
plt.plot(x_len, y_loss, marker='.', c="blue", label='Trainset_loss')
- Epochs = 5 일 때,
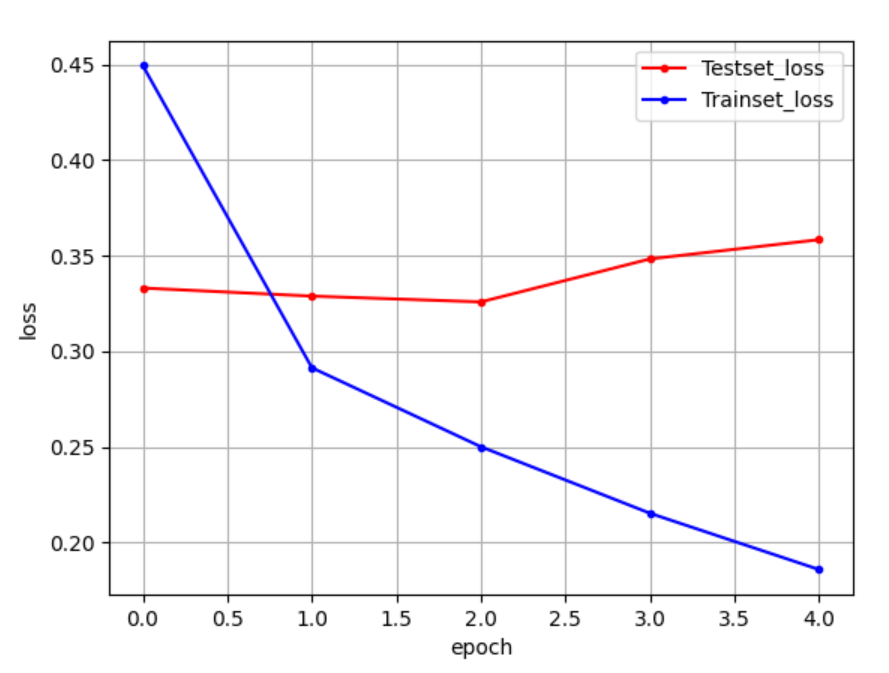
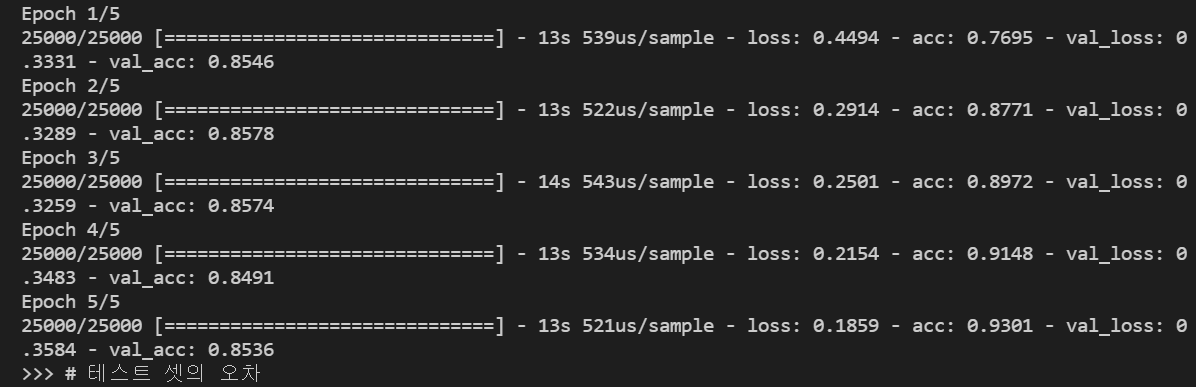
epoch=5로 돌렸을 때
trainset의 loss(오차) 값은 계속 하락하지만
testset의 loss(오차) 값은 0.33 ~ 0.35로 살짝 상승하고 있어서, 과적합이 발생하고 있음을 보여준다.
- Epochs = 20 일 때,
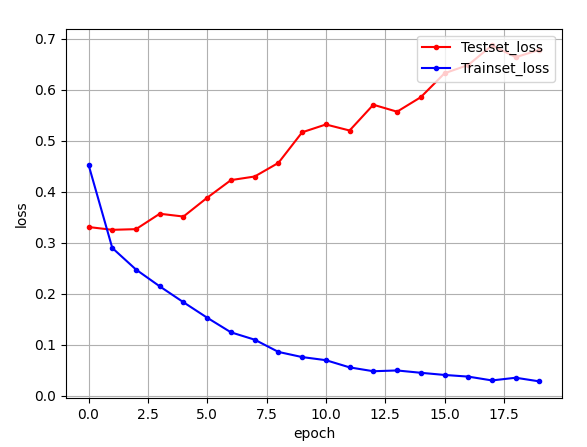
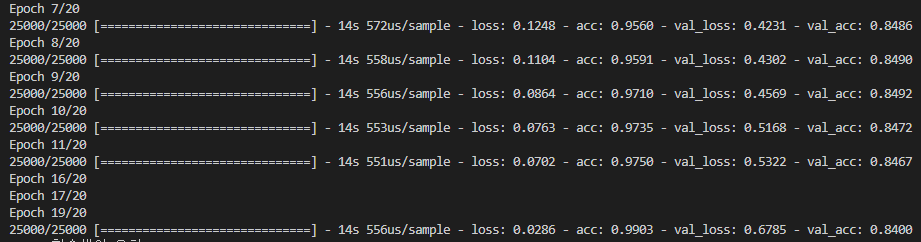
epoch=20로 돌렸을 때
trainset의 loss(오차) 값은 0.45로 시작하여 0.1 이하로 계속 하락하지만
testset의 loss(오차) 값은 0.33 ~ 0.65까지 계속 상승하여 과적합이 계속 커짐을 알 수 있다.
'머신러닝딥러닝 > 딥러닝' 카테고리의 다른 글
| 코사인 유사도(Cosine Similarity)vs 유클라디안 유사도(Euclidean Similarity)vs 자카드 유사도(Jaccard Similarity) (0) | 2022.11.28 |
|---|---|
| t-SNE vs UMAP 차원 축소 알고리즘 알아보기 (0) | 2022.06.27 |
| 딥러닝(Deep Learning) #15 - RNN (0) | 2022.04.15 |
| 딥러닝(Deep Learning) #14 - CNN (0) | 2022.04.15 |
| 딥러닝(deel learning) #13 - 선형회귀 적용하기 (0) | 2022.04.14 |




댓글