순환신경망(Recurrent Neural Network, RNN)

순환신경망은 여러개의 데이터가 순차적으로 입력되었을 때,
앞서 입력받은 데이터를 잠시 기억해 놓는 방법을 사용한다.
기억된 데이터가 얼마나 중요한지 판단하여 가중치를 준 뒤, 다음 데이터로 넘어간다.
모든 입력 값에 기억, 판단, 가중치 부여 작업을 실행함으로 같은 층 안에서 계속 맴도는 성질 때문에 순환신경망이라고 부른다.
RNN의 문제점
1.
RNN은 LSTM(Long Short Term Memory)방법과 함께 가장 많이 사용되고 있다.
LSTM(Long Short Term Memory)
RNN의 한 종류로, 긴 의존기간을 필요로 하는 학습을 수행할 능력을 갖추고 있음.
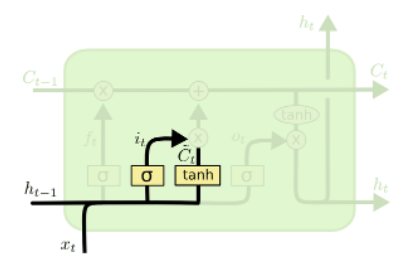
LSTM 구동순서
1. CELL STATE
Linear interaction 만 적용시키며, 전체체인을 구동시키고 정보가 전혀 바뀌지않고 그대로 흐른다는 특징이 있다.
2. GATE1 = sigmoid layer 층(forget gate layer)
앞으로 들어오는 새로운 정보 중 cell state에 저장할 것을 정하는 gate이다.
GATE2 : input gate layer

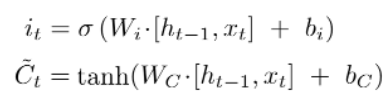
sigmoid layer = 과거 state Ct-1을 업데이트 → 새로운 Cell state Ct를 만듬.
tanh layer = 새로운 후보값 Ct(Vector)를 생성, Cell state 추가 준비
sigmoid, tanh 정보를 합쳐 state에 업데이터 재료를 만든다.
cell state 업데이트
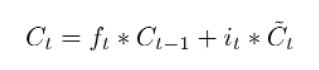
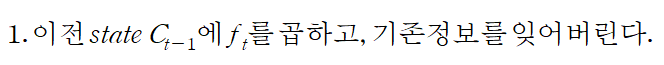
input layer Gate 에서 온 it * Ct를 더한다.
더하는 값 it * Ct는 두번째 단계에서 업데이트하기로 한 값을 업데이트 할지 정한만큼 scale한 값이 된다.
이전 단계에서 정했던 사항들을 실천하는 단계라고 볼 수 있다.
GATE 3 : Output Gate Layer
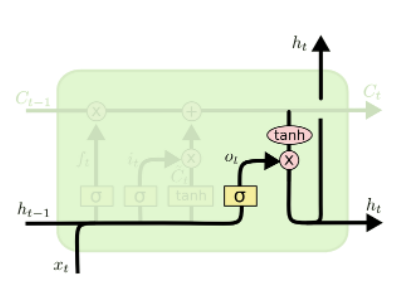
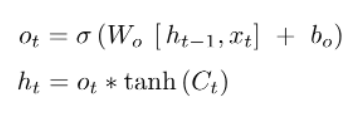
1. sigmoid layer에 input data를 입력 → output으로 보낼 부분 선택
2. cell layer를 tanh layer에 태워 -1 ~ +1 사이의 값으로 만든다.
3. -1 ~ +1 값을 sigmoid Gate의 output과 곱한다.
4. output으로 보내고자 하는 부분만 전송이 가능하다.
LSTM 예제 코드
LSTM 라이브러리 설정
# LSTM = Long Short Term Memory
# RNN
# 로이터 뉴스 카테고리 분석하기
from tensorflow.keras.datasets import reuters
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM, Embedding
from tensorflow.keras.preprocessing import sequence
from tensorflow.python.keras.utils import np_utils
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
# seed 값 고정하기
seed = 0
np.random.seed(seed)
tf.set_random_seed(seed)LSTM 설정에 필요한 라이브러리 LSTM, Embedding, np_utils를 가져온다.
내장 데이터 이용을 위해 reuters를 가져온다.
데이터 가져오기
#데이터 train, test set으로 나누기
# num_words = 1000 -> 1~1000개의 단어만 가져올 것
# test_split : train 80%, test 20%
(x_train, y_train), (x_test,y_test) = reuters.load_data(num_words=1000, test_split=0.2)reuters.load_data(num_word=1000, test_split=0.2)
로이티뉴스 데이터 reuters를 가져오면서 단어가 1000개 이상 넘지 않도록 제한해서 가져온다.
가져온 데이터를 train 80%, test 20%로 분류한다.
데이터 전처리
# 데이터 전처리
# pad_sequence(maxlen) = 단어 수를 100개로 맞춰라
# 단어 > 100 이라면 나머지 버림
# 단어 < 100 이라면 나머지 0으로 채움
x_train = sequence.pad_sequences(x_train, maxlen=100)
x_test = sequence.pad_sequences(x_test, maxlen=100)
# One-Hot Encoding
y_trian = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)pad_sequence() 함수 :
초기 입력과 동일한 크기를 유지되도록 하는 패딩(Padding), 최대 크기를 100으로 맞춰서 패딩한다.
단어 > 100 이라면 나머지 버림
단어 < 100 이라면 나머지 0으로 채움
One_Hot Encoding
y_trian = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)
to_categorical()함수를 이용하여 y_train, y_test 데이터를 [0, 0, 0, 0, 1, 0, ..., 0]로 만든다
# 딥러닝 모델 설정
# Embedding =?
model = Sequential()
model.add(Embedding(1000, 100))
model.add(LSTM(100, activation='tanh'))
model.add(Dense(46, activation='softmax'))
# model.add(Dense(1, activation='sigmoid'))
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 모델 실행
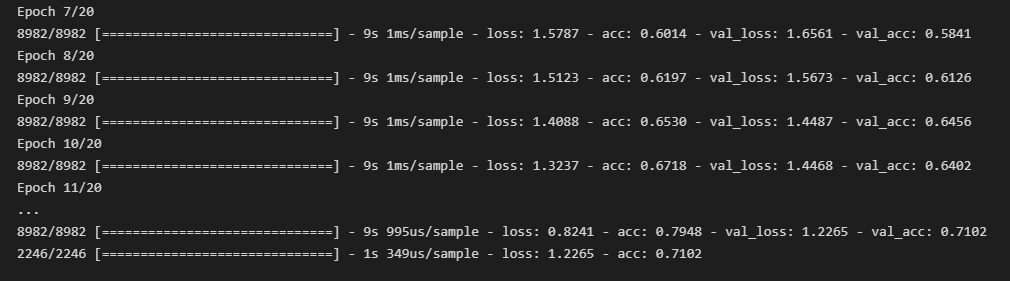
history = model.fit(x_train, y_train, epochs=20, batch_size=50, validation_data=(x_test, y_test))
print("\n Test Accuracy: %.4f" % (model.evaluate(x_test, y_test)[1]))Embedding()
데이터 전처리 과정을 통해 입력된 값을 받아 다음 층이 알아들을 수 있는 형태로 변환하는 역할
모델 설정의 가장 처음 부분에 위치해있어야 한다.
- Embedding('불러온 단어의 총 개수', '기사당 단어 수')
LSTM()
RNN에서 기억 값에 대한 가중치를 제어하는 역할
- LSTM(기사당 단어 수, 기타 옵션)
- LSTM 활성화 함수 : Tanh를 사용
모델 실행
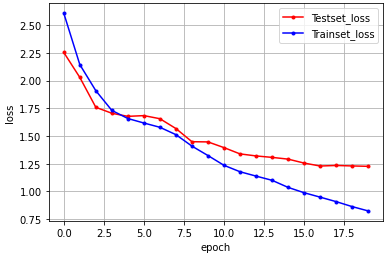
trainset, testset 오차 그래프로 표현하기
# 테스트 셋의 오차
y_vloss = history.history['val_loss']
# 학습셋의 오차
y_loss = history.history['loss']
# 그래프로 표현
x_len = np.arange(len(y_loss))
plt.plot(x_len, y_vloss, marker='.', c="red", label='Testset_loss')
plt.plot(x_len, y_loss, marker='.', c="blue", label='Trainset_loss')
# 그래프에 그리드를 주고 레이블을 표시
plt.legend(loc='upper right')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()테스트 셋의 오차 = 빨간색
훈련 셋의 오차 = 파란색
'머신러닝딥러닝 > 딥러닝' 카테고리의 다른 글
| t-SNE vs UMAP 차원 축소 알고리즘 알아보기 (0) | 2022.06.27 |
|---|---|
| 딥러닝(Deep Learning) #16 - RNN & CNN (0) | 2022.04.17 |
| 딥러닝(Deep Learning) #14 - CNN (0) | 2022.04.15 |
| 딥러닝(deel learning) #13 - 선형회귀 적용하기 (0) | 2022.04.14 |
| 딥러닝(Deep Learning) #12 베스트 모델 구하기 (0) | 2022.04.14 |




댓글