CNN
합성곱 신경망 : Convolutional Neural Network
이미지처리에 탁월한 성능을 가진 신경망.
합성곱 신경망은 합성곱층(Convolution layer) / 풀링층(Pooling layer)로 구성된다.
2. 합성곱(Convolution) 연산 : 이미지의 특징을 추출함
- 커널/필터라는 N X M 크기 행렬로 높이 X 너비 크기의 이미지를 처음부터 끝까지 겹치며 훑으면서 N X M 크기의 겹쳐지는 이미지와 커널 원소 값을 곱해서 모두 더한 값을 출력으로 한다.
- 이미지는 왼쪽위부터 오른쪽 아래 순으로 훑는다.
- 스트라이드(Stride) : 입력데이터 필터 적용 시 이동 간격을 조절 하는 것. 필터가 이동할 간격




최종 결과값 : 특성맵(feature map)
if stride =1 (kernel 움직임 범위)
->?5x5 이미지에 3x3 커널이 움직이고 최종적으로 3x3크기의 특성맵이 얻어짐
if stride =2 (kernel 움직임 범위)
->?5x5 이미지에 3x3 커널이 움직이고 최종적으로 2x2크기의 특성맵이 얻어짐

3. 패딩(Padding)
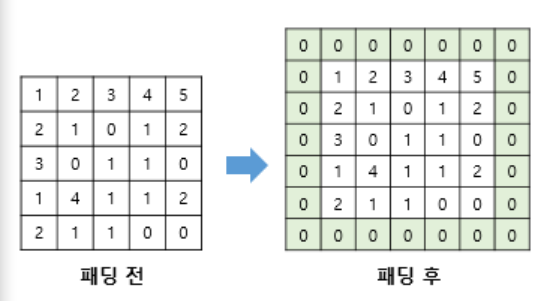
합성곱 연산 이후, 초기 입력과 동일한 크기를 유지되도록 하는 게 패딩(Padding)이다.
합성곱 연산이후 얻는 특성맵은 초기맵보다 크기가 작아진다.
4. 가중치와 편향
합성곱은 커널에 맵핑되는 픽셀만을 입력하여 다중 퍼셉트론보다 적은수의 가중치 사용, 공간적 구조정보를 보존한다는 특징이 있다.
합성곱 신경망의 은닉층은 비선형성 추가를 위해 활성화 함수를 지나게되고, 활성화 함수인 렐루함수 등이 사용되게 된다.
합성곱 연산으로 특성맵을 얻고, 활성화 함수를 지나는 연산을 합성곱층(convolution layer)라고 한다.
5. 특성맵의 크기 계산법
특성 맵의 높이와 너비를 구하는 법
= 입력의 크기, 커널의 크기, 스트라이드의 값으로 특성맵 크기 계산이 가능

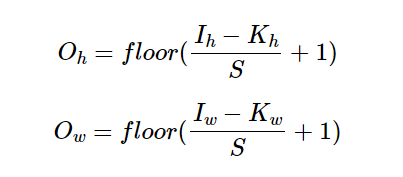
- floor 함수 : 소수점 발생 시 소수점이하를 버리는 역할.
- 5X5 크기 이미지, 3X3 커널, 스트라이드 1 합성곱 연산할 경우,
(5-3+1) X (5 - 3+ 1) = 3 X 3
= 총 9번의 스탭이 필요함
패딩의 폭을 P라고 할 때, 패딩까지 고려한 식은 다음과 같다.
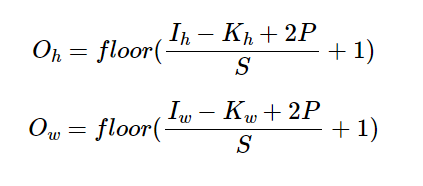
6. 3차원 텐서 합성곱 연산(다수의 채널 합성곱 연산)
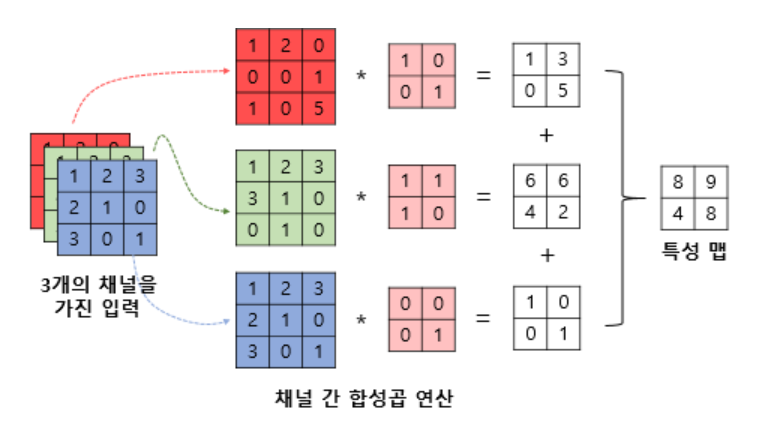
3개의 채널, 3개의 커널, 각 1개씩 합성곱 3개 → 합성곱 3개 더하기 → 특성맵 2x2 도출
input = 높이 3, 너비3, 채널3
kernel = 높이 2, 너비2, 채널 3
합성곱 연산 = 높이 2, 너비2, 채널 1 결과 도출
7. 3차원 텐서의 합성곱 연산

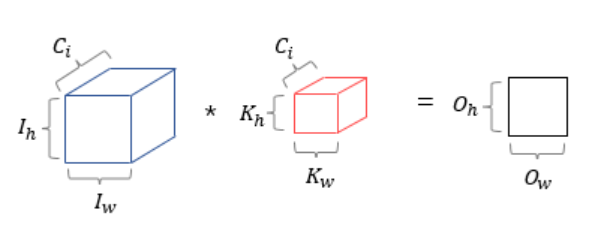
3차원 텐서의 합성곱 연산...
다수커널을 사용한 합성곱 연산
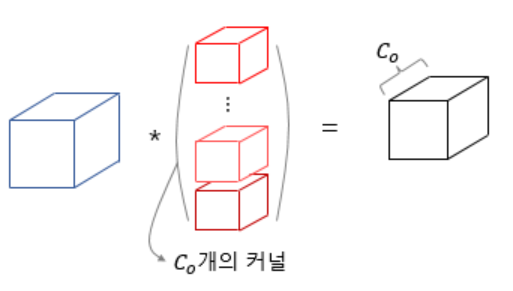
n개의 커널을 이용한 합성곱 연산을 진행할 경우, 사용한 커널의 개수는 특성맵의 채널 수가 된다.
사용한 커널의 개수 = 특성맵의 채널 수

8. 풀링 POOLING
합성곱 층 : 합성곱 연산 후 활성화 함수를 거치는 layer
풀링 층(Pooling)
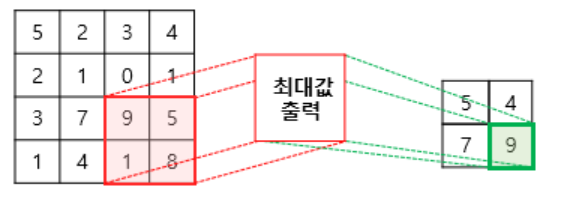
합성곱 층 이후 풀링층을 추가하는 게 일반적이다.
특성 맵은 다운샘플링하여 특성맵의 크기를 줄이는 풀링연산이 이뤄진다.
- 풀링연산 : 특성 맵의 크기를 줄이는 연산
- 맥스풀링 : 커널과 겹치는 영역 안에서 최대값을 추출하는 방식으로 다운 샘플링함.
- 평균풀링 : 커널과 겹치는 영역 안에서 평균값을 추출하는 방식으로 다운 샘플링함.
딥러닝 기본 프레임 만들기
라이브러리 설정
# CNN
# 라이브러리 설정
import pandas as pd
import numpy as np
import sys
import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow.python.keras.utils import np_utils
# seed 값 설정
seed = 0
np.random.seed(seed)
tf.set_random_seed(seed)keras.datasets import mnist : mnist 데이터 불러오기
keras.utils import np_utils : np_utils : to_categorical()함수로 One-Hot encoding 수행
# MNIST 데이터 불러오기
(X_train, Y_train), (X_test, Y_test) = mnist.load_data()
X_train = X_train.reshape(X_train.shape[0], 784).astype('float32') / 255
X_test = X_test.reshape(X_test.shape[0], 784).astype('float32') / 255
Y_train = np_utils.to_categorical(Y_train, 10)
Y_test = np_utils.to_categorical(Y_test, 10)내장 데이터 mnist : 손글씨 70000개가 담긴데이터 셋
mnist.load_data() : 내장데이터 mnist 데이터를 load 한다.
X_train, X_test 변환 :
- 1. 28x28 = 764개의 속성을 이용해 0~9개 클래스를 맞추는 내용으로 변경
- 2. reshape() 함수를 이용해 가로세로 28 X 28을 1차원 배열로 바꾼다.
- 3. 0~255 값 → 0~1값으로 변경 → X_train.reshape(X_train.shape[0], 784).astype('float64') / 255
- 4. print("class : %d" % (Y_class_train[0]) = class : 5
Y_train, Y_test 변환:
1. 열어본 이미지 Y_class_train[0] = 5 → to_categorical() 함수로 [0,0,0,0,1,0,0,0,0]로 변경
2. 반환된 값 출력 시 [0,0,0,0,1,0,0,0,0]로 변경 확인
# 모델 프레임 설정
model = Sequential()
model.add(Dense(512, input_dim=784, activation='relu'))
model.add(Dense(10, activation='softmax'))
# 모델 실행 환경 설정
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])X_train 데이터가 784개의 속성, 10개의 클래스를 가지고 있다.
입력값 input_dim = 784, 은닉층 512개, 출력은 10개인 모델
오차값 loss = sparse_categorical_crossentropy 사용
- 이유 : categorical_crossentropy 입력할 경우 오류 발생, 시스템의 sparse_categorical_crossentropy 이용 추천
sparse categorical crossentropy vs categorical crossentropy 차이
- sparse categorical_crossentropy : 각 샘플이 하나의 class에 속할 때 사용
- categorical_crossentropy : 각 샘플이 여러개 class에 속할 수 있거나 label이 soft probablities일 때 사용하는 게 좋다.
# 모델 최적화 설정
MODEL_DIR = 'C:/Users/kwonk/juno1412-1/juno1412/DL/모두의 딥러닝/model/'
if not os.path.exists(MODEL_DIR):
os.mkdir(MODEL_DIR)
modelpath='C:/Users/kwonk/juno1412-1/juno1412/DL/모두의 딥러닝/model/{epoch:02d}-{val_loss:.4f}.hdf5'
checkpointer = ModelCheckpoint(filepath=modelpath, monitor='val_loss', verbose=1, save_best_only=True)
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=10)os.path.exists() : 해당 디렉토리, 폴더에 존재하면 True, 없으면 False
os.mkdir : 폴더 생성
checkpointer = ModelCheckpoint(filepath=modelpath, monitor='val_loss', verbose=1, save_best_only=True)
: filepath 위치의 오차범위가 나아지지 않으면 나타내지 않는다.
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=10)
오차값이 10번까지 나아지지 않으면 시행을 멈춘다.
# 모델의 실행
history = model.fit(X_train, Y_train, validation_data=(X_test, Y_test), epochs=30, batch_size=200, verbose=0, callbacks=[early_stopping_callback,checkpointer])
# 테스트 정확도 출력
print("\n Test Accuracy: %.4f" % (model.evaluate(X_test, Y_test)[1]))
# 테스트 셋의 오차
y_vloss = history.history['val_loss']
# 학습셋의 오차
y_loss = history.history['loss']loss : 훈련 손실값
acc : 훈련 정확도
val_loss : 검증 손실값
val_acc : 검증 정확도
# 그래프로 표현
x_len = numpy.arange(len(y_loss))
plt.plot(x_len, y_vloss, marker='.', c="red", label='Testset_loss')
plt.plot(x_len, y_loss, marker='.', c="blue", label='Trainset_loss')
# 그래프에 그리드를 주고 레이블을 표시
plt.legend(loc='upper right')
# plt.axis([0, 20, 0, 0.35])
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()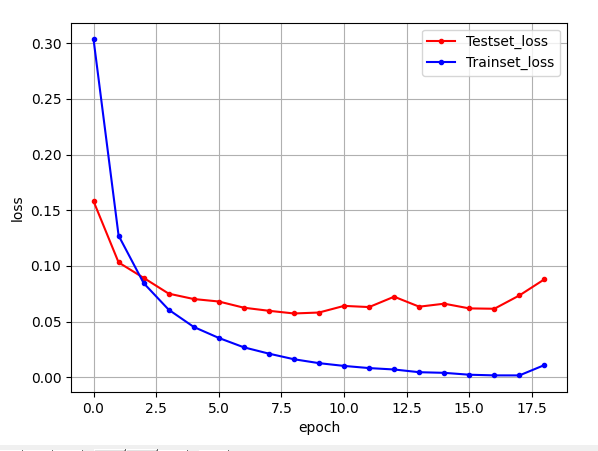
CNN 딥러닝 모델링
라이브러리 설정
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D
from tensorflow.keras.callbacks import ModelCheckpoint,EarlyStopping
import matplotlib.pyplot as plt
import numpy
import os
import tensorflow as tf
# seed 값 설정 = 값 고정
seed = 0
numpy.random.seed(seed)
tf.set_random_seed(seed)CNN 딥러닝 구성을 위해서, keras 라이브러리들 추가
# MNIST 데이터 불러오기
(X_train, Y_train), (X_test, Y_test) = mnist.load_data()
# 데이터 바꾸기
X_train = X_train.reshape(X_train.shape[0], 28, 28, 1).astype('float64') / 255
X_test = X_test.reshape(X_test.shape[0], 28, 28, 1).astype('float64') / 255
Y_train = to_categorical(Y_train, 10)
Y_test = to_categorical(Y_test, 10)mnist 내부 데이터 불러오기
X_train, X_test 변환 :
- 1. 28x28 = 764개의 속성을 이용해 0~9개 클래스를 맞추는 내용으로 변경
- 2. reshape() 함수를 이용해 가로세로 28 X 28을 1차원 배열로 바꾼다.
- 3. 0~255 값 → 0~1값으로 변경 → X_train.reshape(X_train.shape[0], 28, 28, 1).astype('float64') / 255
- 4. print("class : %d" % (Y_class_train[0]) = class : 5
Y_train, Y_test = to_categorical() 함수를 이용하여 1차원 데이터 One-Hot Encoding으로 변경해준다.
1. 열어본 이미지 Y_class_train[0] = 5 → to_categorical() 함수로 [0,0,0,0,1,0,0,0,0]로 변경
2. 반환된 값 출력 시 [0,0,0,0,1,0,0,0,0]로 변경 확인
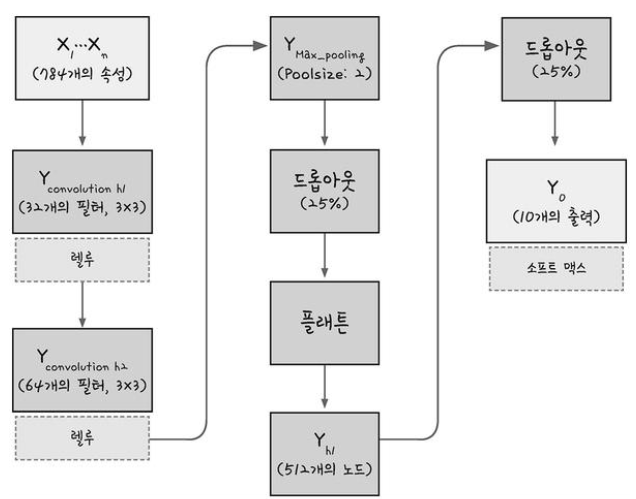
# 모델 프레임 설정/ / 컨볼루전 신경망(CNN)
model = Sequential()
model.add(Conv2D(32, kernel_size=(3,3), input_shape=(28,28,1), activation='relu'))
model.add(Conv2D(64, (3,3), activation='relu'))Conv2D() : keras의 컨볼루젼 층을 추가하는 함수
model.add(Conv2D(32, kernel_size=(3,3), input_shape=(28,28,1), activation='relu'))
1. 32 : 마스크(커널)의 적용 개수 32개, 여러개 커널 적용 시 다른 컨볼루션이 여러개 나온다.
2. kernel_size : kernel_size = (행, 렬), 3X3 크기의 커널 적용
3. input_data : input_data = (행, 렬, 색상 or 흑백), 가장 처음 입력되는 데이터
4. activation = 활성화함수 지정
model.add(MaxPooling2D(pool_size=2))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
# 모델 컴파일
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])MaxPooling2D() : 정해진 구역 안에서 가장 큰 값만 다음층으로 넘기는 작업 수행.
- pool_size : 풀링 창의 크기 2 = 전체 크기 절반
Drop out() : 은닉층에 배치된 노드 중 일부를 랜덤하게 끔으로서 학습데이터에 치우쳐 학습되는 과적합을 방지함.
- 컨볼루션, 맥스풀링은 주어진 이미지를 2차원 배열인 상태로 다룸
Flatten() : 다차원 배열을 1차원으로 변경해주는 함수
모델 최적화 설정
MODEL_DIR = 'C:/Users/kwonk/juno1412-1/juno1412/DL/모두의 딥러닝/model/'
if not os.path.exists(MODEL_DIR):
os.mkdir(MODEL_DIR)
modelpath='C:/Users/kwonk/juno1412-1/juno1412/DL/모두의 딥러닝/model/{epoch:02d}-{val_loss:.4f}.hdf5'
checkpointer = ModelCheckpoint(filepath=modelpath, monitor='val_loss', verbose=1, save_best_only=True)
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=10)
# 모델의 실행
history = model.fit(X_train, Y_train, validation_data=(X_test, Y_test), epochs=30, batch_size=200, verbose=0, callbacks=[early_stopping_callback,checkpointer])
# 테스트 정확도 출력
print("\n Test Accuracy: %.4f" % (model.evaluate(X_test, Y_test)[1]))os.path.exists() : 해당 디렉토리, 폴더에 존재하면 True, 없으면 False
os.mkdir : 폴더 생성
checkpointer = ModelCheckpoint(filepath=modelpath, monitor='val_loss', verbose=1, save_best_only=True)
: filepath 위치의 오차범위가 나아지지 않으면 나타내지 않는다.
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=10)
오차값이 10번까지 나아지지 않으면 시행을 멈춘다.
# 테스트 셋의 오차
y_vloss = history.history['val_loss']
# 학습셋의 오차
y_loss = history.history['loss']
# 그래프로 표현
x_len = numpy.arange(len(y_loss))
plt.plot(x_len, y_vloss, marker='.', c="red", label='Testset_loss')
plt.plot(x_len, y_loss, marker='.', c="blue", label='Trainset_loss')
# 그래프에 그리드를 주고 레이블을 표시
plt.legend(loc='upper right')
# plt.axis([0, 20, 0, 0.35])
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()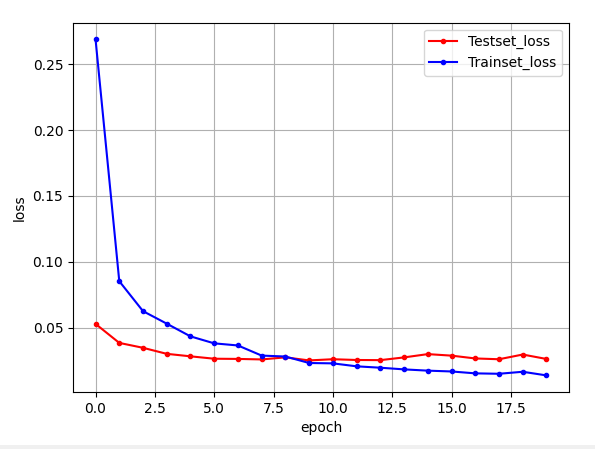
참고 사이트 : https://wikidocs.net/64066
1) 합성곱 신경망(Convolution Neural Network)
합성곱 신경망(Convolutional Neural Network)은 이미지 처리에 탁월한 성능을 보이는 신경망입니다. 하지만 합성곱 신경망으로 텍스트 처리를 하기 위한 시 ...
wikidocs.net
'머신러닝딥러닝 > 딥러닝' 카테고리의 다른 글
| 딥러닝(Deep Learning) #16 - RNN & CNN (0) | 2022.04.17 |
|---|---|
| 딥러닝(Deep Learning) #15 - RNN (0) | 2022.04.15 |
| 딥러닝(deel learning) #13 - 선형회귀 적용하기 (0) | 2022.04.14 |
| 딥러닝(Deep Learning) #12 베스트 모델 구하기 (0) | 2022.04.14 |
| 딥러닝(Deep learning) #10 다중 분류 (0) | 2022.04.13 |




댓글