베스트 모델구하기
기본 와인데이터 확인 및 딥러닝 프레임워크 완성하기
# 베스트 모델 구하기
# 기본 데이터 확인 및 딥러닝 모델 만들기
# 라이브러리 설정
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.callback import ModelCheckpoint, EarlyStopping
# seed=0 고정설정
seed = 0
np.random.seed(seed)
tf.set_random_seed(seed)
# 데이터 확인 및 분석
data_wine = pd.read_csv("C:/Users/kwonk/juno1412-1/juno1412/DL/모두의 딥러닝/dataset/wine.csv", header=None)
wine = data_wine.sample(frac=1) # frac =1 ? frac = 전체 row에서 몇%의 데이터를 return할 건지 설정
# 데이터 속성, 결론 값 dataset 설정하기
# 12개속성, 1개의 클래스
wine_df = wine.values
X = wine_df[:,0:12]
Y = wine_df[:, 12]
# 딥러닝 모델설정
model = Sequential()
model.add(Dense(30, input_dim=12, activation='relu'))
model.add(Dense(12, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# 딥러닝 모델 컴파일&실행
model.compile(loss = 'binary_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(X, Y, epochs=200, batch_size=100)
# 결과값 출력하기
print("\n Accuracy: %.4f" % (model.evaluate(X,Y)[1]))
모델 설정 및 저장하기
모델 저장 및 재사용 + epoch마다 모델의 정확도를함께 기록하며 저장해준다.
import os
# 모델 설정
MODEL_DIR = 'C:/Users\kwonk/juno1412-1/juno1412/DL/모두의 딥러닝/model/' # 저장 폴더 생성하기
if not os.path.exists(MODEL_DIR):
os.mkdir(MODEL_DIR)
modelpath = "C:/Users\kwonk/juno1412-1/juno1412/DL/모두의 딥러닝/model/{epoch:02d}-{val_loss:4f}.hdf5"modelpath = "/model/{epoch:02d}-{val_loss:4f}.hdf5"
epoch 횟수, 테스트셋 오차값을 이용해 파일이름 생성, '.hdf'라는 확장자로 저장하기
모델 저장 설정하기
from keras.callbacks mport movelCheckpoint
checkpointer = ModelCheckpoint(filepath=modelpath, monitor='val_loss', verbose=1, safe_best_only=True)model.fit(X, Y, validation_split=0.2, epochs=200, batch_size=200, verbose=0, callbacks=[checkpointer])
X, Y 데이터로 모델을 실행
validation_split = train set, test set 비율나누기
callback = 1 epoch가 끝날 때마다 path에 자동으로 저장해줌, 현재는 1~199까지 200개 모델 저장됨.
그래프 시각화 확인하기
checkpointer = ModelCheckpoint(filepath=modelpath, monitor='val_loss', verbose=1, safe_best_only=True)
history = model.fit(X, Y, validation_split=0.33, epochs=3500, batch_size=500)
# Y의 오차값
y_vloss = history.history['val_loss']
# Y읠 정확도
y_acc = history.history['acc']
# 결과값 시각화
# 값 지정 후, 정확도는파란색 오차는 파랑색
x_len = np.arange(len(y_acc))
plt.plot(x_len, y_vloss,"o", c='red', markersize =3)
plt.plot(x_len, y_acc,"o", c='blue', markersize =3)
# 결과값 출력하기
plt.show()history.history() : 결과물을 시각화 시키는 함수
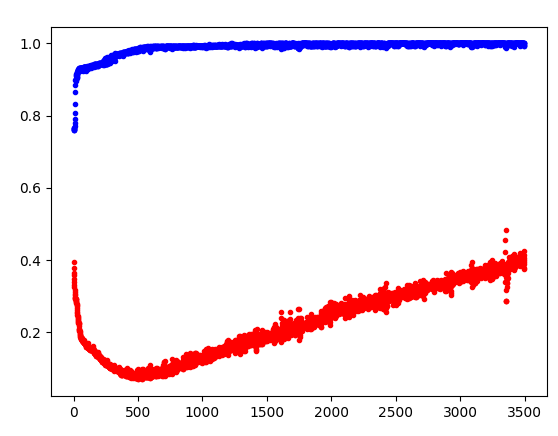
파란색선 = Y의 테스트 데이터는 계속 올라가서 1에 수렴한다. 데이터를 훈련하면 1에 가까워진다.
하지만 빨간색선 = 테스트 결과는 어느정도 시간이 흐르면 더 나아지지 않고 오차가 늘어남 -> 과적합
자동 멈춤 기능
# 라이브러리 추가
from tensorflow.keras.callbacks import EarlyStopping
# 자동중단 설정
# 오차가 100 이상에 도달하면 자동으로 중단한다.
early_stopping_callback = EarlyStopping(monitor='val_loss', patience = 100)
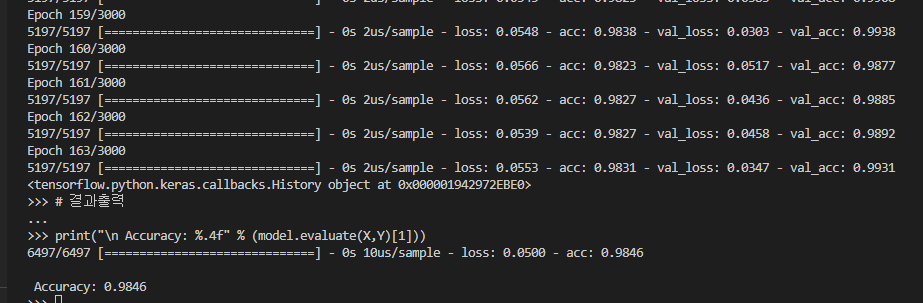
model.fit(X, Y, validation_split=0.2, epochs=3000, batch_size=500, callbacks=[early_stopping_callback])
# 결과출력
print("\n Accuracy: %.4f" % (model.evaluate(X,Y)[1]))
from tensorflow.keras.callbacks import EarlyStopping
keras의 EarlyStopping 라이브러리를 추가해서 자동중단 설정을 할 수 있는 환경설정을 마무리한다.
EarlyStopping(monitor='val_loss', patience = 100)
: EarlyStopiing은 'val_loss'가 100이 넘으면 자동으로 연산을 멈춘다.
model.fit 에서 트레인셋, 테스트셋 비율, 반복 횟수, 배치사이즈를 지정하고, 자동중단 기준을 100으로 설정해준다.
'머신러닝딥러닝 > 딥러닝' 카테고리의 다른 글
| 딥러닝(Deep Learning) #14 - CNN (0) | 2022.04.15 |
|---|---|
| 딥러닝(deel learning) #13 - 선형회귀 적용하기 (0) | 2022.04.14 |
| 딥러닝(Deep learning) #10 다중 분류 (0) | 2022.04.13 |
| 딥러닝(Deep learning) #9 데이터 분석 & 피마 인디언 당뇨병 예측 (0) | 2022.04.13 |
| 딥러닝(Deep learning) #8 모델 설계 keras (0) | 2022.04.13 |




댓글