pose estimation의 산출데이터 3가지
Mediapipe의 pose estimation 기능은 3가지 데이터를 추출하여 결과값으로 활용할 수 있다. 3가지 데이터는 pose_landmarks, pose_world_landmarks, segmentation_mask 이다.
pose_landmarks
pose_landmarks 좌표는 1point 좌표당 x, y, z의 좌표값과 visibillity 4가지 데이터를 받을 수 있다.한 사진의 포즈에서 skeleton 정보를 33개 뽑을 수 있으니 33 point의 132가지 정보를 추출할 수 있다.
- x, y 좌표 값 : 각각 이미지 너비와 높이로 0.0 ~ 1.0 사이값으로 정규화된 랜드마크 좌표
- z 좌표 값 : 엉덩이 중간지점 깊이를 원점으로 하는 랜드마크 깊이를 나타냄. 값이 작으면 카메라에 가까워지고 x좌표와 같은 척도를 사용하는 좌표값. 엉덩이 중심점과 카메라와의 거리 측정 후 0.0 ~ 1.0 사이값으로 정규화된 랜드마크 좌표
- visibility : 0.0~1.0 값으로 이미지에서 랜드마크가 보이는 가능성(가리지 않은 가능성)을 나타내는 값
단, 중심점 기준으로 뒤로 갈 경우 -1.0 ~ 0.0으로 표시되기 때문에, x,y,z 좌표값은 -1.0~1.0 값으로 표시됨
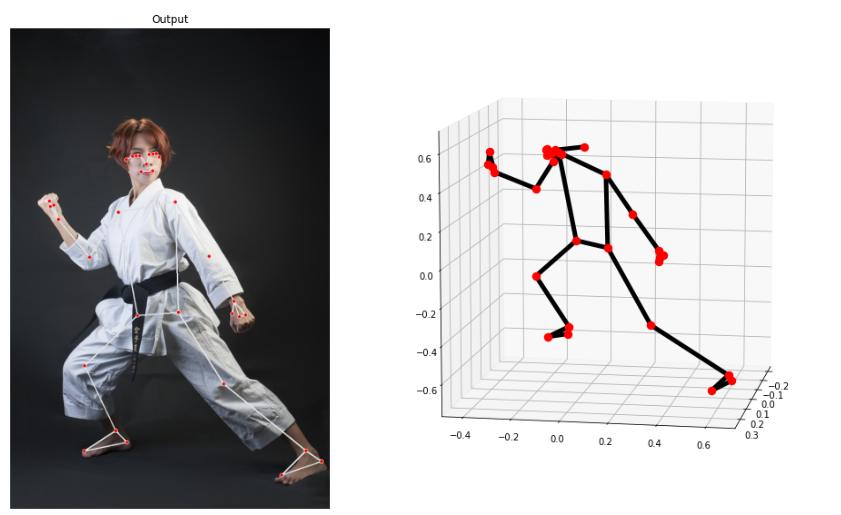
pose_world_landmarks

pose_world_landmarks 좌표는 pose_landmarks와 동일하게 1point 좌표당 x, y, z의 좌표값과 visibillity 4가지 데이터를 받아 한 사진의 포즈에서 skeleton 정보를 33개 뽑을 수 있으니 33 point의 132가지 정보를 추출할 수 있다.
다만 pose_landmarks와 다른점은 실제 세계의 거리 값을 기준으로 landmarks의 x,y,z 좌표를 추출한다는 점이다. 대상이 되는 사람을 detect한 뒤, 사람의 엉덩이를 중심점(0.0)으로 잡고 미터단위로 조정하여 x, y, z 값을 추출하여 [-1.0, 1.0]까지 추출하게 된다.
- x, y, z 좌표 값 : 실제 3D 좌표를 엉덩이를 중심점으로 0.0 ~ 1.0 사이값으로 정규화된 랜드마크 좌표
단, 중심점 기준으로 뒤로 갈 경우 -1.0 ~ 0.0으로 표시되기 때문에, x,y,z 좌표값은 -1.0~1.0 값으로 표시됨
- visibility : 0.0~1.0 값으로 이미지에서 랜드마크가 보이는 가능성(가리지 않은 가능성)을 나타내는 값
segmentation_mask
segmentation mask란 분할 마스크로 pose estimation 수행 시, parameter인 [enable_segmentation]이 설정되어야만 출력되는 분할 마스크이다.
segmentation mask는 input된 image와 동일한 너비, 높이를 가지고 '인간', '배경' 픽셀의 높은 가능성을 나타내는 값을 [0.0, 1.0] 값으로 나타냅니다.

mediapipe의 pose estimation solution에서 pose world landmarks를 사용하는 이유는 사람과 실제 거리를 반영한 데이터이기 때문이다.
pose landmarks에 사용되는 video의 너비와 높이를 정규화한 데이터는 비디오마다 너비와 높이가 다를 수 있다는 점과 video마다 사람이 위치하는 location point가 다르면 그에따라서 같은 동작임에도 불구하고 다른 데이터가 추출될 수 있는 우려 때문에 pose world landmarks를 사용하게 되었다.
pose world landmarks는 사람의 엉덩이를 중심에 두고 실제 거리를 미터단위로 측정하여 0.0~1.0 사이로 정규화한 값이기 때문에, video의 너비와 높이 그리고 사람의 lacation에 영향을 받지 않기 때문이다.
'머신러닝딥러닝 > detection' 카테고리의 다른 글
| mediapipe human detection crop image 미디어파이프 사람인식 및 crop image (1) | 2023.12.04 |
|---|---|
| human pose recoginition vanila lstm model vs 가변 길이 lstm model (0) | 2023.03.10 |
| Mediapipe pose estimation BrazePose 33 landmarks 정보 추출하기 (1) | 2023.02.09 |
| mediapipe - face detect & pose estimation 동시 실행하기 (0) | 2023.01.20 |
| mediapipe face detect - webcam 실시간 실행하기 (0) | 2023.01.19 |




댓글