BrazePose

BlazePose : On-device Real-time Body Pose Tracking
2020년 google에서 발표한 논문으로 실시간으로 한 명의 사람을 pose estimation하는 기능을 모바일 기기에서 처리하기 위한 솔루션이다.
BlazePose는 얼굴, 몸통을 포함하여 눈, 코, 입 등 얼굴 주요부위와 손, 어깨, 무릎, 엉덩이 등 몸 주요부위에 해당하는 33개의 점으로 나타내고 33개의 landmarks를 보여주는 것이 목표이다.

BlazePose는 실시간 detect에서 우수한 성능을 보여주는 detector-tracker 방식을 사용하였다.
pipeline은 lightweight body pose detector와 pose tracker network로 구성되어 있는데, tracker는 key point의 좌표와 사람의 존재 여부를 감지한다. 사람이 없다면 다음 frame에서 detect network를 실행시키게 된다.
Detector는 얼굴을 통해서 사람의 존재를 분석하는데, 사람의 얼굴이 가장 감지하기 쉽기 때문이라고 말한다. 그리고 몸의 반지름, 허리와 수직선 사이의 각도를 예측하는데 이것을 pose alignment라고 한다.
pose alignment은 tracker에 들어갈 사람 image의 scale과 rotation을 보정하기 위해 사용된다.
Mediapipe pose estimation 33landmarks
Mediapipe의 pose estimation은 Blaze pose를 이용하여 수화, 요가, 운동 등 경량화 모바일 single tracker 모델이다.
Mediapipe pose estimation은 cpu에서 실시간으로 사용할 수 있고, 특히 mobile device의 GPU에서는 더 빠르게 작동한다는 장점을 가지고 있다.
Mediapipe의 pose estimation 솔루션에서 사용하고 있는 pose landmarks model은 BlazePose model을 사용한다.
신체 주요부위 관절 33개의 Landmarks를 추출하는 방식으로 신체 부위의 location을 나타낼 수 있다.

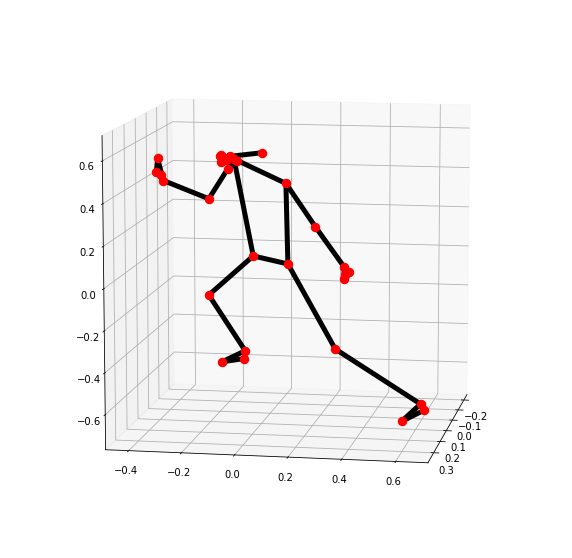
Mediapipe를 이용한 pose estimation을 수행하게 되면 33개의 landmarks 각 위치마다 x,y,z의 3차원 좌표값과 visibility 가시성 정보까지 총 132개의 정보를 받을 수 있다.
3차원 좌표값을 plot으로 나타내면 위 사진처럼 3차원 공간 안에 위치한 33개 landmarks에 대한 x,y,z 좌표값으로 나타낸 사람의 blazepose 모양을 확인할 수 있다.
Mediapipe pose estimation landmarks pose data 추출하기
import cv2
import mediapipe as mp
mp_drawing = mp.solutions.drawing_utils
mp_drawing_styles = mp.solutions.drawing_styles
mp_pose = mp.solutions.pose
# 빈 dataframe 생성
df = pd.DataFrame()
# webcam / video 불러오기
cap = cv2.VideoCapture('C:/Users/kwonk/Downloads/workspace/data_files/youtube_running.mp4')
with mp_pose.Pose(
min_detection_confidence=0.5,
min_tracking_confidence=0.5) as pose:
while cap.isOpened():
success, image = cap.read()
if not success:
print("Ignoring empty camera frame.")
# video라면 break, webcam이라면 continue
break
# To improve performance, optionally mark the image as not writeable to
# pass by reference.
image.flags.writeable = False
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
results = pose.process(image)
# pose data 저장
# 빈 리스트 x 생성
x = []
# k = landmarks 개수 및 번호
# results.pose_landmarks.landmark[k].x/y/z/visibility로
# k번째 landmarks의 정보를 가져올 수 있다.
for k in range(33):
x.append(results.pose_landmarks.landmark[k].x)
x.append(results.pose_landmarks.landmark[k].y)
x.append(results.pose_landmarks.landmark[k].z)
x.append(results.pose_landmarks.landmark[k].visibility)
# list x를 dataframe으로 변경
tmp = pd.DataFrame(x).T
# dataframe에 정보 쌓아주기
# 33개 landmarks의 132개 정보가 dataframe에 담긴다.
df = pd.concat([df, tmp])
# Draw the pose annotation on the image.
image.flags.writeable = True
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
mp_drawing.draw_landmarks(
image,
results.pose_landmarks,
mp_pose.POSE_CONNECTIONS,
landmark_drawing_spec=mp_drawing_styles.get_default_pose_landmarks_style())
# Flip the image horizontally for a selfie-view display.
cv2.imshow('MediaPipe Pose', cv2.flip(image, 1))
if cv2.waitKey(5) & 0xFF == 27:
break
cap.release()영상이나 image 파일을 읽고 pose.process로 나온 result를 확인하면 result내부에 landmarks 정보가 저장되어 있다.
result안에 저장되어 있는 landmarks의 순서는 1~33번까지 BlazePose 표에 나와있는 순서대로 저장되어 있고, 33번까지 순서대로 가져와서 저장해주면 왼쪽 눈부터 시작해서 발 끝까지의 landmarks x,y,z,visibillity 정보를 확인할 수 있다.
landmarks data를 sequence data로 변환하기

위 코드로 쌓은 landmarks 정보는 index가 sequence 형태로 0~10, 0~20 형식으로 쌓여있지 않고 동영상을 20장씩 잘라낸 이미지의 pose landmarks 정보가 그대로 쌓여있는 것을 확인할 수 있다.
class로 구분되어 있지만 index로 sequence를 구분해주지 않으면 class별로 lstm 모델에 들어갈 때 구분이 힘들기 때문에 sequence 형태로 변형해주기로 한다.
def data_cleaning():
# 전역변수 불러오기
# pose_class = image 20장의 landmarks information file
global pose_class
# 전역변수 변수명 변경
df = pose_class
# class 별 data 개수 확인 -> class별 400개 데이터 필요
print(df['class'].value_counts())
# class 제거 후 value만 남기기
df_2 = df.drop(['class'], axis=1).reset_index(drop=True)
# 빈 데이터프레임 생성
df_se1 = pd.DataFrame()
df_se2 = pd.DataFrame()
df_se3 = pd.DataFrame()
df_se4 = pd.DataFrame()
df_se5 = pd.DataFrame()
# class별 sequence 1~20 data 순서대로 dataframe으로 저장
for i in range(1,21):
df_tmp = df_2[20*(i-1):20*i].reset_index(drop=True)
df_se1 = pd.concat([df_se1, df_tmp], axis=0)
for i in range(21,41):
df_tmp = df_2[20*(i-1):20*i].reset_index(drop=True)
df_se2 = pd.concat([df_se2, df_tmp], axis=0)
for i in range(41,61):
df_tmp = df_2[20*(i-1):20*i].reset_index(drop=True)
df_se3 = pd.concat([df_se3, df_tmp], axis=0)
for i in range(61,81):
df_tmp = df_2[20*(i-1):20*i].reset_index(drop=True)
df_se4 = pd.concat([df_se4, df_tmp], axis=0)
for i in range(81,101):
df_tmp = df_2[20*(i-1):20*i].reset_index(drop=True)
df_se5 = pd.concat([df_se5, df_tmp], axis=0)
df_se1['class'] = 'Fall_down'
df_se2['class'] = 'Phone_call'
df_se3['class'] = 'Reading'
df_se4['class'] = 'Running'
df_se5['class'] = 'Squats'
df_se = pd.concat([df_se1, df_se2, df_se3, df_se4, df_se5], axis=0)
df_se.to_csv('C:/Users/kwonk/Downloads/workspace/data_files/sequense_5pose_only5_total.csv')
return df_sepose class는 fall_down, running, reading, squats, phone_call 5가지 class 의 동영상을 이미지로 분할하여 landmarks 정보로 변형하여 저장이 되어있다.
모든 class에 20개의 샘플 동영상을 가져왔으므로 20번씩 반복하고, 1개의 샘플 영상당 20장의 이미지에 20개의 skeleton data가 쌓이니 1개의 클래스당 400개의 skeleton data가 차례대로 쌓인다.
1개의 영상에 대한 20개의 skeleton data가 쌓일 때마다 reset_index()를 해주어 0~19까지 시퀀스로 index 정보가 변경되도록 해주었다.
각 class별 sequence data를 dataframe에 각각 따로 de_se1, de_se2 , ... , de_se5 같이 따로 저장한다.
따로 저장한 dataframe 들을 concat 함수를 이용해서 모두 합해주고 csv로 저장하면 5가지 pose에 대한 20번씩 sequence별로 skeleton data가 저장되어있는 csv파일을 생성할 수 있다.
'머신러닝딥러닝 > detection' 카테고리의 다른 글
| human pose recoginition vanila lstm model vs 가변 길이 lstm model (0) | 2023.03.10 |
|---|---|
| mediapipe pose estimation data : pose_landmarks VS pose_world_landmarks (0) | 2023.02.23 |
| mediapipe - face detect & pose estimation 동시 실행하기 (0) | 2023.01.20 |
| mediapipe face detect - webcam 실시간 실행하기 (0) | 2023.01.19 |
| mediapipe pose classification model - webcam streaming environment (0) | 2023.01.18 |




댓글