입력층 은닉층 출력층
Sequential() 힘수
- Sequential()을 모델로 선언하고 model.add()라는 라인을 추가하면 새로운 층 형성가능.
- Sequential 모델은 각 레이어에 정확히 하나의 입력 텐서와 하나의 출력 텐서가 있는 일반 레이어 스택에 적합합니다.
model.add() 함수 : 새로운 층을 만드는 함수
Dense()함수 : model.add()로 새로운 층 생성 후, Dense()함수를 통해 몇개의 노드를 만들 건지 지정함.
- (Dense(30, input_dim=17, activation='relu'))
= Dense(30개의 노드), input_dim(폐암환자 생존여부 데이터 17개를 노드로 보냄), activation = 'relu'(활성화 함수)

# 딥러닝 모델 설정
# 입력층 : Sequential()
model = Sequential()
# 은닉층 : 30개의 노드, 17개의 입력값(폐암환자 속성), relu 활성화함수(기울기소실 ↓ 속도↑)
model.add(Dense(30, input_dim=17, activation='relu'))
# 출력층 : 노드 1개 = 출력 값 1개, sigmoid 활성화함수
model.add(Dense(1, activation='sigmoid'))
모델 컴파일
model.compile()은 지정한 딥러닝모델이 효과적으로구현될 수 있는 환경설정 + 컴파일하는 과정이다.
model.compile(loss) : 오차함수 사용
model.compile(optimizer) : 최적화 방법
model.compile(metrics) :
모델 컴파일 될 때, 모델 수행결과를 나타내게끔 설정하는 부분. 정확도 측정 시 사용되는 test sample을 제외시켜 과적합문제를 방지하는 기능이다.
# 딥러닝 컴파일&훈련
model.compile(loss='mean_squared_error', optimizer='adam', metrics=['accuracy'])오차함수 loss = 'mean_squared_error'
MSE 평균제곱오차 함수는 수렴하기까지 시간이 오래걸리고 속도가 느리다는 단점이 있다.
교차 엔트로피로 오차함수를 바꾸면, 오차가 커질경우 수렴속도가 빨라지고 오차가 작아지면 속도가 감소하게 된다.
최적화함수 optimizer = 'adam'

교차엔트로피
교차엔트로피는 분류 문제에서 많이 사용된다.
특별히 예측값이 참/거짓 둘 중 하나인 형식일 때, binary_crossentropy(이항 교차 엔트로피) 사용한다.
현재 결과도출은 생존(1) / 사망(0) 이므로 binary_crossentropy(이항 교차 엔트로피)를 사용하기 알맞다.
model.compile(loss='mean_squared_error', optimizer='adam', metrics=['accuracy'])
→ model.compile(loss='binary_crossentropy', optimizer='adam', metrics = ['accuracy'])
- loss=mean_squared_error를 사용했을 때,
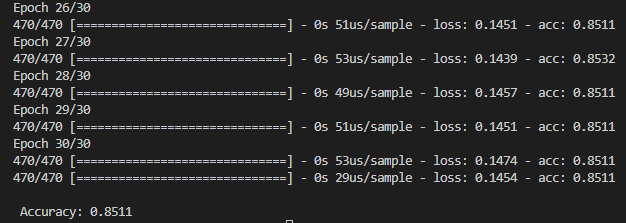
- loss=binary_crossentropy를 사용했을 때,

loss 함수 2개를 사용했을 때 정확도는 0.8511로 동일하나
loss율이 많이 차이가 나온 걸 볼 수 있다.
대표적 오차함수
| 평균제곱계열 | mean_squared_error | 평균제곱오차 - mean(squared(yt-yo)) |
|||
| mean_absolute_error | 평균절대오차 - mean(abs(yt-yo)) |
||||
| mean_absolute_parsentage_error | 평균 절대 백분율 오차 - mean(abs(yt-yo)/abs(yt)) (단, 분모 ≠ 0) |
||||
| mean_squared_logarithmic_error | 평균 제곱 로그 오차 - mean(square(log(yo) + 1) - (log(yt) + 1)) |
||||
| 교차 엔트로피 | categorical_crossentropy | 범주형 교차 엔트로피(일반적 분류) | |||
| binary_crossentropy | 이항 교차 엔트로피 | ||||
모델 실행하기
model.fit() : model.compile 단계에서 정해진 환경에서 데이터로 실행시킬 때 사용되는 함수
# 딥러닝 실행
model.fit(x, y, epochs=30, batch_size=10)주어진 데이터 : 470명의 폐암 수술환자의 생존 여부와 속성(17개)가 담긴 데이터
epoch = 100 : 각 샘플이 처음부터 끝까지 100번 재사용될 때까지 실행을 반복
batch_size = 샘플을 한번에 몇개씩 처리할 지 정함. batch_size = 10은 샘플을 10개씩 끊어서 넣음
batch_size가 크면 속도↓, 작으면 실행값의 편차↑ 결과값 불안정
'머신러닝딥러닝 > 딥러닝' 카테고리의 다른 글
| 딥러닝(Deep learning) #10 다중 분류 (0) | 2022.04.13 |
|---|---|
| 딥러닝(Deep learning) #9 데이터 분석 & 피마 인디언 당뇨병 예측 (0) | 2022.04.13 |
| 딥러닝(Deeping Learning) #7 - 오차 역전파/신경망 (0) | 2022.04.12 |
| 딥러닝(Deep Learning) #6 - 퍼셉트론 (0) | 2022.04.12 |
| 딥러닝(deeplearning) #5 - 다항 로지스틱 회귀(Multi_Logistic_Regression) (0) | 2022.04.12 |




댓글