surprise library
surprise library는 python 언어에 기반하여 추천시스템 구현에 특화된 라이브러리 입니다.
scikit-learn API와 비슷한 형태로 제공하는 라이브러리이기도 합니다.
Surprise library process : [data loading → model set & train → predict & test]
1) data loading
- surprise library를 제작할 때, movielens라는 open DataSet을 이용하여 만들어진 추천시스템입니다.
- 그러므로 movielens의 format과 같은 'user - item - rating'의 순서에 맞추어 동일하게 맞추어야 라이브러리가 작동하게 됩니다
2) model set & train
- surprise library 모델은 KNN(최근접이웃) & SVD(잠재요인) & Baseline 등의 모델을 선정하고 학습합니다.
3) predict & test
- 학습된 모델을 이용해서 test 데이터로 예측하고 평가합니다.
surprise algorithm
1. svd(), svdpp 특이값 분해 알고리즘
특이값 분해란 특정 행렬(matrix)를 분해하여 singular value(특이값)을 가지는 행렬로 분해하는 알고리즘을 말합니다.


A X B의 DATA 행렬이 있다면
해당 행렬 Matrix를 분해하여, One-Hot encoding 형태로 나오는 특이값을 구해주는 알고리즘입니다.
SVD()를 이용하면 A X B Matrix를 U, S(Singular value), V로 분해하게 됩니다.
S(Singular value)는 해당 영화/유저/콘텐츠 등을 파악할 수 있는 특이값을 나타내는 value 입니다.
일정차원 축소 : truncated SVD
SVD(n_factors = 'n')
from surprise import SVD
from surprise import Dataset
# 데이터 불러오기
data = Dataset.load_builtin(dataset)
algo = SVD()
algo.fit(data)
# Run 5-fold cross-validation and print results
cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
KNNBasic algorithm
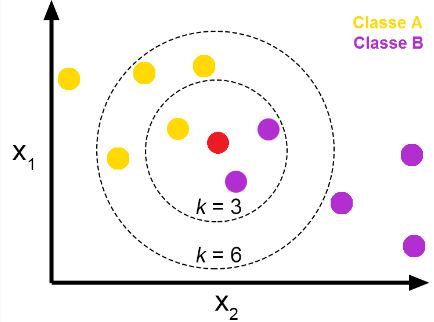
algo = KNNBasic(k=40, min_k=1, sim_options={'name': 'msd', 'user_based': True})- k : 가까운 이웃의 최대 개수(기본값 : 40개)
- min_k : 이웃의 최소 개수, 유사도가 0보다 큰 이웃의 최소 개수에 미달할 경우 평점의 기본값으로 추정
- sim_options : 'user_based' = True or 'item_based' = False
from surprise import KNNBasic
from surprise import Dataset
# Load the movielens-100k dataset
data = Dataset.load_builtin('ml-100k')
# Retrieve the trainset.
trainset = data.build_full_trainset()
# Build an algorithm, and train it.
algo = KNNBasic()
algo.fit(trainset)
# KNNBasic
algo = KNNBasic(k=40, min_k=1, sim_options={'name': 'msd', 'user_based': True})
KNNBaseline only
KNNBasic과 차이점은 k명의 유사 사용자들이 영화 i에 대해 평가한 평점들을 그대로 가중합하지않고,
(rv∈k,i−μv∈k) 를 가중합하게 된다.
그리고 최종적으로는 우리가 영화 i에대해 예측하려는 사용자 U의 평균을 더해주는 방법으로 사용자 U의 특성을 좀 더 부가하는 방법을 쓰고 있다.
예를들어 U는 원래 평점을 조금 낮게주는 스타일이어서 정말 재밌다고 느끼는 영화에도 4점을 준다고 가정해보자.
k명의 유사 유저들이 영화 i에 대해 다 5점을 줬단 이유로
5점에 가까운 예측 값이 나오게 된다면 문제가 발생할 수 있게 되는 것이다.
KNNwithBaseline에서는 유사 유저들의 평점을 추종하는 문제를 완화해준다.

Slope One
- new item/ other item 중 사용자 선호의 평균적인 값의 차이에 기반해서 새로운 선호를 추정하는 algorithm입니다.
- 단순 선호 추정, 유사도 측정 X
- A, B사이의 평점 차이 계산 ((4.0-2.0)+(3.0-4.0))/2 = +1.0

| 해리포터 | 반지의 제왕 | |
| 사용자 A | 3.0 | 4.0 |
| 사용자 B | 평가하지 않음 예측평점 : 3.0 + 1.0 = 4.0 |
3.0 |
BaselineOnly
사용자 아이디 uu, 상품 아이디 ii, 두 개의 카테고리 값 입력에서
평점 r(u,i)r(u,i)의 예측치 r^(u,i)을 예측하는 가장 단순한 회귀분석모형으로
다음과 같이 사용자와 상품 특성에 의한 평균 평점의 합으로 나타난다.
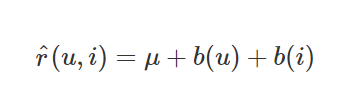
y(predict) = a*x1(x1=user) + a*x2(x2=item) + 평균평점
μμ는 전체 평점의 평균이고, b(u)b(u)는 동일한 사용자에 의한 평점 조정값, b(i)b(i)는 동일한 상품에 대한 평점 조정값
- BaselineOnly algorithm은 주어진 사용자/아이템을 기반으로 추정치를 예측합니다.
- user_id, content_id 2개의 요소(x값)만으로 평점의 예측치를 계산합니다.
- 다중 선형회귀 모델(x가 여러개 존재하는 y값 추정하는 모델)
- μ : 전체 평점 평균
- b(u) :동일한 사용자에 의한 평점 조정값
- b(i) : 동일 상품에 대한 평점 조정값
코사인 유사도 VS 피어슨 유사도


코사인의 각도가 작을 수록 유사도가 높다고 판단한다
코사인 유사도는 유저별로 가지는 속성을 걸러내지 못하는 단점이 있다.
- - USER A [1, 1, 1, 1, 1]
- - USER B [10, 10, 10, 10, 10]
이런 경우 코사인 유사도는 1이다.
피어슨 유사도

피어슨 유사도를 이용하면 코사인 유사도의 유저속성을 걸러내지 못하는 단점을 완화할 수 있다.
Pearson은 두 벡터의 상관계수를(pearson correlation coefficient)를 말한다.
cosine과 비슷한하지만, 차이점은 r에서 그 사용자의 평균을 빼줘서 user별로 가지는 성격은 상대적으로 제거한 방식의 metric으로 볼 수 있다
'주홍의 프로젝트 > 연습 프로젝트' 카테고리의 다른 글
| 추천시스템의 고질적 단점 cold start 개요, 해결방법 (0) | 2022.07.13 |
|---|---|
| surprise 라이브러리 algorithm 정리 (0) | 2022.06.29 |
| 추천 시스템 정리 (0) | 2022.06.29 |
| Neural Network Embedding Recommendation System (kaggle) review (0) | 2022.06.23 |
| 사용자기반 협업 필터링 추천시스템 - 애니메이션 추천시스템 (1) | 2022.06.22 |




댓글