surprise library
surprise library는 python 언어에 기반하여 추천시스템 구현에 특화된 라이브러리 입니다.
scikit-learn API와 비슷한 형태로 제공하는 라이브러리이기도 합니다.
Surprise library process : [data loading → model set & train → predict & test]
1) data loading
- surprise library를 제작할 때, movielens라는 open DataSet을 이용하여 만들어진 추천시스템입니다.
- 그러므로 movielens의 format과 같은 'user - item - rating'의 순서에 맞추어 동일하게 맞추어야 라이브러리가 작동하게 됩니다
2) model set & train
- surprise library 모델은 KNN(최근접이웃) & SVD(잠재요인) & Baseline 등의 모델을 선정하고 학습합니다.
3) predict & test
- 학습된 모델을 이용해서 test 데이터로 예측하고 평가합니다.
surprise algorithm
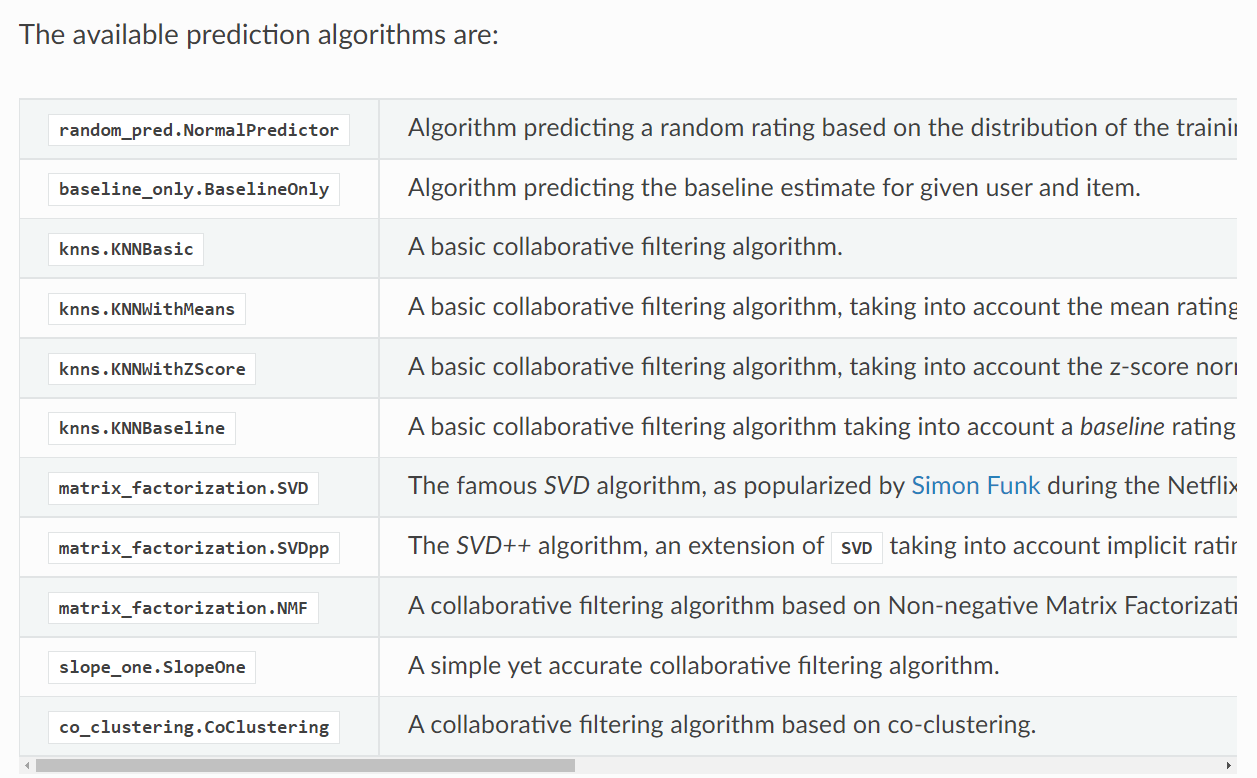
1. Basic algorithms
① NormalPredictor
- NormalPredictor algorithm은 정규화된 trainset을 기반으로 무작위로 점수를 예측합니다.
- 가장 기본적인 알고리즘 중 하나
② BaselineOnly
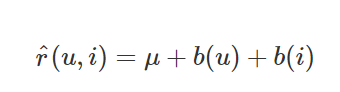
- BaselineOnly algorithm은 주어진 사용자/아이템을 기반으로 추정치를 예측합니다.
- user_id, content_id 2개의 요소(x값)만으로 평점의 예측치를 계산합니다.
- 다중 선형회귀 모델(x가 여러개 존재하는 y값 추정하는 모델)
- μ : 전페 평점 평균
- b(u) :동일한 사용자에 의한 평점 조정값
- b(i) : 동일 상품에 대한 평점 조정값
2. K-NN(K-Nearest Neighbor, 최근접이웃) algorithms
KNN은 item/user vector와 유사한 k개의 vector를 이용하여 user의 rating을 예측하는 방법입니다.
① KNNBASIC
- KNNBASIC은 Collaborative filtering 의 기본적인 알고리즘입니다.

algo = KNNBasic(k=40, min_k=1, sim_options={'name': 'msd', 'user_based': True})- k : 가까운 이웃의 최대 개수(기본값 : 40개)
- min_k : 이웃의 최소 개수, 유사도가 0보다 큰 이웃의 최소 개수에 미달할 경우 평점의 기본값으로 추정
- sim_options : 'user_based' = True or 'item_based' = False
② KNNWithMeans
- KNNWithMeans은 Collaborative filtering 의 기본적인 알고리즘으로, 각 유저의 평균 점수를 이용합니다.
③ KNNWithZScore
- KNNWithZScore은 Collaborative filtering 의 기본적인 알고리즘으로, 각 유저의 z-score 정규화를 이용합니다.
- Z-score(표준화 점수) : 평균과 표준편차가 정의되었을 때, 데이터가 얼마나 벗어나있는지 측정하는 지표 데이터의 평균, 표준편차를 계산하여 데이터 평균을 0.0, 표준편차를 1.0으로 만드는 기법입니다. Z-score ↑ 이상치 가능성↑
④ KNNBaseline
- KNNBaseline은 Collaborative filtering 의 기본적인 알고리즘으로, Baseline rating을 이용합니다.
3. matrix Factorization-based algorithms(use pivot table)
① SVD
- 가장 유명한 SVD algorithm으로 baseline을 사용하지 않고 확률적 행렬분해를 이용합니다.
- 사용자 특성, 상품 특성 N개의 요인 중 공통점이 많을수록 평점은 높아집니다.
② SVDpp(SVD++)
- implicit rating을 포함하여 SVD를 계산한 확장형 SVD algorithm
- implicit data : 유저가 간접적으로 선호,취향을 나타내는 데이터 ex) 검색기록, 구매내역, 장바구니 등... NOPE
- SVDpp의 imlicit data란 user가 1~5점의 평점을 주어진 행위 자체가 user의 implicit data를 포함하기 때문에 user의 implicit data가 있다고 생각하고 미리 계산하는 방식
③ NMF
- 마이너스 값(부정적인 값)이 없는 Non-negative Matrix Factorization을 베이스로 이용하는 collaborative filtering algorithm
④ Slope One
- new item/ other item 중 사용자 선호의 평균적인 값의 차이에 기반해서 새로운 선호를 추정하는 algorithm입니다.
- 단순 선호 추정, 유사도 측정 X
- A, B사이의 평점 차이 계산 ((4.0-2.0)+(3.0-4.0))/2 = +1.0
| 해리포터 | 반지의 제왕 | |
| 사용자 A | 4.0 | 2.0 |
| 사용자 B | 3.0 | 4.0 |
| 사용자 C | 평가하지 않음 예측평점 : 3.0 _ 1.0 = 4.0 |
3.0 |
⑤ Co-clustering -...??
- 공동 클러스터링(군집)기반의 collaborative filtering algorithm
- Co-clustering : 공동 군집 분석
dataset으로 surprise algorithms 평가하기(rmse, mse)
dataset = ml-100k, ml-1m, jester 3개 고정
1. 라이브러리 설정하기
# 라이브러리 설정
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import time
import datetime
import random
import numpy as np
import six
from tabulate import tabulate
from surprise import Dataset
from surprise.model_selection import cross_validate
from surprise.model_selection import KFold
from surprise import NormalPredictor, BaselineOnly, KNNBasic, KNNWithMeans, KNNBaseline, SVD, SVDpp, NMF, SlopeOne, CoClustering
2. cross-validate할 class 설정하기(성능평가 classes 설정)
# The algorithms to cross-validate
classes = (SVD, SVDpp, NMF, SlopeOne, KNNBasic, KNNWithMeans, KNNBaseline,
CoClustering, BaselineOnly, NormalPredictor)surprise algorithm인 SVD, SVDpp, NMF, SlopeOne, KNNBasic, KNNWithMeans, KNNBaseline, CoClustering, BaselineOnly, NormalPredictor을 모두 class에 넣어줍니다.
3. surprise link로 algorithms 불러오기
# ugly dict to map algo names and datasets to their markdown links in the table
stable = 'http://surprise.readthedocs.io/en/stable/'
LINK = {'SVD': '[{}]({})'.format('SVD',
stable +
'matrix_factorization.html#surprise.prediction_algorithms.matrix_factorization.SVD'),
'SVDpp': '[{}]({})'.format('SVD++',
stable +
'matrix_factorization.html#surprise.prediction_algorithms.matrix_factorization.SVDpp'),
'NMF': '[{}]({})'.format('NMF',
stable +
'matrix_factorizaytion.html#surprise.prediction_algorithms.matrix_factorization.NMF'),
'SlopeOne': '[{}]({})'.format('Slope One',
stable +
'slope_one.html#surprise.prediction_algorithms.slope_one.SlopeOne'),
'KNNBasic': '[{}]({})'.format('k-NN',
stable +
'knn_inspired.html#surprise.prediction_algorithms.knns.KNNBasic'),
'KNNWithMeans': '[{}]({})'.format('Centered k-NN',
stable +
'knn_inspired.html#surprise.prediction_algorithms.knns.KNNWithMeans'),
'KNNBaseline': '[{}]({})'.format('k-NN Baseline',
stable +
'knn_inspired.html#surprise.prediction_algorithms.knns.KNNBaseline'),
'CoClustering': '[{}]({})'.format('Co-Clustering',
stable +
'co_clustering.html#surprise.prediction_algorithms.co_clustering.CoClustering'),
'BaselineOnly': '[{}]({})'.format('Baseline',
stable +
'basic_algorithms.html#surprise.prediction_algorithms.baseline_only.BaselineOnly'),
'NormalPredictor': '[{}]({})'.format('Random',
stable +
'basic_algorithms.html#surprise.prediction_algorithms.random_pred.NormalPredictor'),
### ml-100k, ml-1m, jester 3가지 데이터 셋만 가능
# surprise 라이브러리 고정
# 고치려면 surprise/dataset.py 소스코드를 변경해야함
'ml-100k': '[{}]({})'.format('Movielens 100k',
'http://grouplens.org/datasets/movielens/100k'),
'ml-1m': '[{}]({})'.format('Movielens 1M',
'http://grouplens.org/datasets/movielens/1m'),
}### ml-100k, ml-1m, jester 3가지 데이터 셋만 가능
# surprise 라이브러리 고정
# 고치려면 surprise/dataset.py 소스코드를 변경해야함
'ml-100k': '[{}]({})'.format('Movielens 100k',
'http://grouplens.org/datasets/movielens/100k'),
'ml-1m': '[{}]({})'.format('Movielens 1M',
'http://grouplens.org/datasets/movielens/1m'),알고리즘을 불러오는 링크 뒤에는 dataset을 불러오는 링크를 작성합니다.
surprise의 dataset.py에는 ml-100k, ml-1m, jester dataset을 불러오는 기능이 내장되어 있습니다.

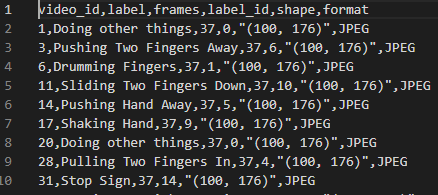
ml-100k
ml-1m
: user_id, item_id, rating, timestamp 4개 data가 담긴 dataset
jester
: video_id, label, frames, label_id, shape, format 6개 data가 담긴 jester
위 3개가 아닌 다른 링크나 폴더를 불러오기 할 경우, 알 수 없는 dataset이라고하며 오류가 발생하게 됩니다.
4. seed 값 고정하기
# 시드 고정 = 모든 알고리즘이 같은 데이터로 성능평가하기 위함
# set RNG
np.random.seed(0)
random.seed(0)random값 seed를 고정합니다.
모든 알고리즘이 같은 데이터와 순서로 성능평가할 수 있도록 seed값을 고정합니다.
5. 데이터셋 불러오기
dataset = 'ml-100k'
data = Dataset.load_builtin(dataset)
kf = KFold(random_state=0) # folds will be the same for all algorithms.
6. algorithm cross-validate & view
table = []
for klass in classes:
start = time.time()
out = cross_validate(klass(), data, ['rmse', 'mae'], kf)
cv_time = str(datetime.timedelta(seconds=int(time.time() - start)))
link = LINK[klass.__name__]
mean_rmse = '{:.3f}'.format(np.mean(out['test_rmse']))
mean_mae = '{:.3f}'.format(np.mean(out['test_mae']))
new_line = [link, mean_rmse, mean_mae, cv_time]
print(tabulate([new_line], tablefmt="pipe")) # print current algo perf
table.append(new_line)
header = [LINK[dataset],
'RMSE',
'MAE',
'Time']
print(tabulate(table, header, tablefmt="pipe"))
'주홍의 프로젝트 > 연습 프로젝트' 카테고리의 다른 글
| 추천시스템의 고질적 단점 cold start 개요, 해결방법 (0) | 2022.07.13 |
|---|---|
| surprise 라이브러리 알고리즘 정리 (0) | 2022.07.04 |
| 추천 시스템 정리 (0) | 2022.06.29 |
| Neural Network Embedding Recommendation System (kaggle) review (0) | 2022.06.23 |
| 사용자기반 협업 필터링 추천시스템 - 애니메이션 추천시스템 (1) | 2022.06.22 |




댓글