영화 추천 시스템
넷플릭스 추천시스템 - 사용자기반 협업 필터링
이용 데이터 : netflix pizza data
kaggle에 있는 netflix pizza data를 이용하여 추천시스템을 제작 연습을 해보았습니다.

https://www.kaggle.com/datasets/netflix-inc/netflix-prize-data
Netflix Prize data
Dataset from Netflix's competition to improve their reccommendation algorithm
www.kaggle.com
1. 라이브러리 설정
# 라이브러리 설정
import pandas as pd
import numpy as np
import math
import re
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.sparse import csr_matrix
from surprise import Reader, Dataset, SVD
from surprise.model_selection import cross_validate # cross_validate = evaluate -> surprise 버전 변경으로 변경됨
sns.set_style("ticks")
2. 데이터셋 불러오기 & 시각화
# 데이터셋 가져오기
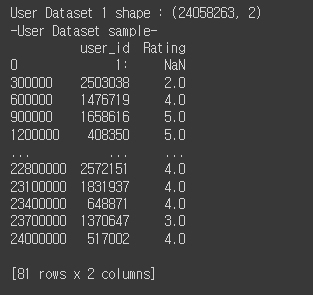
user_data1 = pd.read_csv('./drive/MyDrive/netflix_recommendation/combined_data_1.txt', header = None, names=['user_id', 'Rating'], usecols = [0,1])
user_data1['Rating'] = user_data1['Rating'].astype(float)
print('User Dataset 1 shape : {}'.format(user_data1.shape))
print('-User Dataset sample-')
print(user_data1.iloc[::300000, :])
conbined_data_1.txt가 있는 폴더를 지정하여,
conbined_data의 첫번째, 두번째 컬럼만 ['user_id', 'Rating']이라는 컬럼명을 붙여서 가져옵니다.
Rating 컬럼은 astype() 함수를 이용하여, type을 float(실수형)으로 변경합니다.
# 데이터 시각화
# agg() : 모든 열에 함수를 매핑
data_view = user_data1.groupby('Rating')['Rating'].agg(['count'])
data_view
# movie, user, rating count
# nunique() = 고유값 구하기
movie_count = user_data1.isnull().sum()[1] # 결측값 합산
# nunique() = 총 고유값의 개수(결측값 포함 x)
user_count = user_data1['user_id'].nunique() - movie_count
rating_count = user_data1['user_id'].count() - movie_count결측값을 찾아주는 isnull()함수를 sum()함수로 합산하여 결측값을 계산합니다.
user_count = nunique() 함수로 총 고유값의 개수를 찾고, 결측값인 movie_count를 빼서 고유값을 구합니다.
rating_count = 'user_id'의 숫자를 카운팅 한 개수를 찾고, 결측값을 빼서 평가한 개수를 구합니다.
# 평점 분포도 시각화
ax = data_view.plot(kind='barh', legend = False, figsize = (15,10))
plt.title('Total : {:,} Movies, {:,} customers, {:,} ratings given'.format(movie_count, user_count, rating_count), fontsize=20)
plt.axis('off')
for i in range(1,6):
ax.text(data_view.iloc[i-1][0]/4, i-1, 'Rating {}: {:.0f}%'.format(i, data_view.iloc[i-1][0]*100 / data_view.sum()[0]), color = 'white', weight = 'bold')

1~5 평가 데이터의 분포를 확인할 수 있습니다.
3. 데이터 전처리
3-1. 결측 데이터 제거
# 데이터 전처리
# 결측 데이터 제거
data_nan = pd.DataFrame(pd.isnull(user_data1.Rating)) # 결측치
data_nan = data_nan[data_nan['Rating'] == True] # rating == True 값만 가져오기
data_nan = data_nan.reset_index()
print(data_nan)user_data1의 평가 데이터에서 결측치를 확인하고, True(평가한 영화)만 필터링 합니다.
3-2. 새로운 numpy 배열 만들기
movie_id
movie_np = []
movie_id = 1
for i,j in zip(data_nan['index'][1:], data_nan['index'][:-1]): # [1:] -> 1 ~ 끝 # [:-1] -> 맨 오른쪽 값을 제외한 모든 값
temp = np.full((1,i-j-1), movie_id)
movie_np = np.append(movie_np, temp) # movie_np list =[]에 temp 채우기
movie_id += 1
record = np.full((1,len(user_data1) - data_nan.iloc[-1, 0] - 1), movie_id)
movie_np = np.append(movie_np, record)
print('Movie numpy: {}'.format(movie_np))
print('Length: {}'.format(len(movie_np)))
for i,j in zip(data_nan['index'][1:], data_nan['index'][:-1]): # [1:] -> 1 ~ 끝 # [:-1] -> 맨 오른쪽 값을 제외한 모든 값
temp = np.full((1,i-j-1), movie_id)
movie_np = np.append(movie_np, temp) # movie_np list =[]에 temp 채우기
movie_id += 1

temp = np.full((1, i-j-1), movie_id)
-> 반복문 첫번째 i= 548, j=0 -> 0~548 을 movie_id 1로 채움
-> 반복문 두번째 i= 694, j=548 -> 549~694 을 movie_id 2로 채움
-> movie_id(1~4498)까지 반복
-> 1차원 [1, 1, ..., 2, 2, ..., 4498]
-> 길이 : 24053336의 1차원 데이터 생성
record = np.full((1,len(user_data1) - data_nan.iloc[-1, 0] - 1), movie_id)
movie_np = np.append(movie_np, record)np.full((1,len(user_data1) - data_nan.iloc[-1, 0] - 1), movie_id)
-> (1,len(user_data1) - data_nan.iloc[-1, 0] - 1) = 24057835 - 24053336 -1 = 428개
len(user_data1) = raw data의 total length
data_nan.iloc[-1, 0] = data_nan의 movie_id의 4499 가장 첫번째 줄(= :4499)
'-1' = raw data의 movie_id 구분값 ':4499' 제거
-> 428개 = movie_id : 4499의 rating data 개수
| rating | movie_id | |
| user_id (user_id 순서 =movie_id rating) |
||
| 124(movie_id=0) | 2 | 0 |
| 245(movie_id=0) | 3 | 0 |
| ... | 4 | |
| 621(movie_id=1) | 5 | 1 |
| 846(movie_id=2) | 2 | 2 |
| ... | 3 | |
| 21451(movie_id=25) | 4 | 25 |
| ... | 5 | |
| 24057835 (movie_id=4499) |
1 | 4499 |
3-3. 데이터 유효값 전처리
1) 리뷰가 너무 적은 영화를 제거
2) 리뷰를 너무 적게 제공하는 고객을 제거
# movie/user 최소 유효값 구하기
number = ['count', 'mean']
# movie 최소 유효값 구하기
movie_summary = df.groupby('movie_id')['Rating'].agg(number)
movie_summary.index = movie_summary.index.map(int)
movie_mark = round(movie_summary['count'].quantile(0.9),0) # quantile 분위값 구하기
remove_movie_list = movie_summary[movie_summary['count'] < movie_mark].index
print('Movies minimum times of review: {}'.format(movie_mark))
# user 최소 유효값 구하기
user_summary = df.groupby('user_id')['Rating'].agg(number)
user_summary.index = user_summary.index.map(int)
user_mark = round(user_summary['count'].quantile(0.9),0) # quantile 분위값 구하기
remove_user_list = user_summary[user_summary['count'] < user_mark].index
print('Users minimum times of review: {}'.format(user_mark))
# 데이터 소거
# ~df = is not in(여집합)
print('Original Shape: {}'.format(df.shape))
df = df[~df['movie_id'].isin(remove_movie_list)]
df = df[~df['user_id'].isin(remove_user_list)]
print('After Trim Shape: {}'.format(df.shape))
df.head(5)
영화에 달린 최소 리뷰 11423개
유저가 남긴 리뷰 132개
위 조건에 부합하는 영화와 유저만 필터링하여 2400만개에서 727만 여개로 데이터를 전처리했습니다.
4. 피벗테이블 정의
## 데이터 셋 피벗테이블 정리
df_pivot = pd.pivot_table(df,values = 'Rating', index = 'user_id', columns = 'movie_id')
df_pivot
print(df_pivot.shape)
행 : user_id, 열 : movie_id, 내용 : Rating 데이터로 피벗테이블을 만들어주었습니다.
5. 영화 제목 데이터 가져오기(movie_titles.csv)
## 데이터 mapping
# movie_titles.csv 가져오기
movie_title = pd.read_csv('/content/drive/MyDrive/netflix_recommendation/movie_titles.csv', encoding = 'ISO-8859-1', header = None, names = ['movie_id', 'year', 'name'])
movie_title.set_index('movie_id', inplace = True)
print(movie_title.head(10))

movie_title.csv
movie_id와 movie_name이 담긴 영화제목 csv 파일을 읽어옵니다.
6. 10만개의 데이터 가져오기 & 특이값 분해 & 교차검증
reader = Reader()
# 10만개 데이터만 가져오기 -> 속도
# df = 유효값 전처리 데이터
m_data = Dataset.load_from_df(df[['user_id', 'movie_id', 'Rating']][:100000], reader)
# cross_val_score()2400만개 중 10만개의 데이터만 가져옵니다
2400만개를 가져오면 연산시간이 오래걸리고 매번 반복해서 연산하기에는 비효율적이기 때문입니다.
reader = Reader()
surprise Reader()는 user, item, rating, timestamp 순서를 따라 data를 전처리해주어야합니다.
m_data = Dataset.load_from_df(df[['user_id', 'movie_id', 'Rating']][:100000], reader)
10만개 데이터를 reader 형식으로 가져오기
| user_id | movie_id | Rating | |
| 0 | 1 | 412536 | 1 |
| 1 | 1 | 12315 | 2 |
| 2 | 1 | 1530 | 4 |
| 3 | 2 | 125 | 5 |
import pandas as pd
from surprise import NormalPredictor
from surprise import Dataset
from surprise import Reader
from surprise.model_selection import cross_validate
# Creation of the dataframe. Column names are irrelevant.
ratings_dict = {'itemID': [1, 1, 1, 2, 2],
'userID': [9, 32, 2, 45, 'user_foo'],
'rating': [3, 2, 4, 3, 1]}
df = pd.DataFrame(ratings_dict)
# A reader is still needed but only the rating_scale param is requiered.
reader = Reader(rating_scale=(1, 5))
# The columns must correspond to user id, item id and ratings (in that order).
data = Dataset.load_from_df(df[['userID', 'itemID', 'rating']], reader)
# We can now use this dataset as we please, e.g. calling cross_validate
cross_validate(NormalPredictor(), data, cv=2)
algo = SVD()
cross_validate(algo, m_data, measures=['RMSE', 'MAE'], cv=5, verbose=True)

- SVD 특이값 분석
- Cross_Validate = SVD()와 m_data(100k-data)를 5개의 데이터로 나누어, 교차 검증하여 RMSE, MSE 값을 구합니다.
5개의 데이터로 split하여 fold마다 rmse, mse 값을 구합니다.
7. 유효값 데이터 수정하기
df_svd = df[(df['movie_id'] == 4486) & (df['Rating'] == 5)]
df_svd = df_svd.set_index('movie_id')
df_svd = df_svd.join(movie_title)['name']
print(df)
print(movie_title)
print(df_svd)
user_svd = movie_title.copy()
user_svd = user_svd.reset_index()
user_svd = user_svd[~user_svd['movie_id'].isin(remove_movie_list)]
#
user_data = Dataset.load_from_df(df[['user_id', 'movie_id', 'Rating']], reader)
trainset = user_data.build_full_trainset()
algo.fit(trainset)user_svd는 movie_title data를 copy하고, 기존 데이터와 같게 분위값 0.9에 맞춰서 삭제해줍니다.
reader()함수 양식에 맞는 데이터를 Dataset.load_from_df로 전처리합니다.
build_full_trainset()으로 모든 데이터를 학습데이터로 이용할 수 있게 합니다.
trainset을 svd() 함수로 훈련합니다.

8. 평점 예측하기
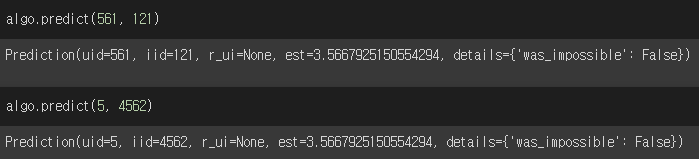
트레이닝을 완료한 svd() 알고리즘 algo를 이용하여
predict() 함수에 user 정보, movie_id를 입력하면 실제 입력 여부와 예측 데이터를 뽑아낼 수 있습니다.
algo.predict() = surprise 형식
uid(user_id), iid(movie_id = item_id), r_ui(read_user_rating), est(predict_rating)로 output을 볼 수 있습니다.
9. 예측 평점 함수 제작
def recommend(title, min_count): # movie_title = title, min_count
print("For movie ({})".format(movie_title))
print("- Top 10 movies recommended based on Pearsons'R correlation - ")
i = int(movie_title.index[movie_title['name'] == title][0])
target = df_pivot[i]
similar_to_target = df_pivot.corrwith(target)
corr_target = pd.DataFrame(similar_to_target, columns = ['PearsonR'])
corr_target.dropna(inplace = True)
corr_target = corr_target.sort_values('PearsonR', ascending = False)
corr_target.index = corr_target.index.map(int)
corr_target = corr_target.join(movie_title).join(movie_summary)[['PearsonR', 'Name', 'count', 'mean']]
print(corr_target[corr_target['count']>min_count][:10].to_string(index=False))피어슨 상관계수를 이용하여 추천 함수를 제작해보겠습니다.
recommend function의 parameter로 볼러올 title[0] = title name과 movie_title.csv 파일의 'name'이 맞는지 확인합니다.
확인한 index 값을 int 값으로 바꿔주고, pivot_table(user_id, movie_id, rating)의 정보를 불러옵니다.
df_pivot.corrwith()는 피벗테이블에서 해당 영화와 다른 영화들의 피어슨 상관계수를 구하는 함수입니다.
상관계수를 내림차순으로 정렬해주고, 해당 영화와 유사도가 높은 영화들을 추천해줍니다.
recommend("X2: X-Men United", 0)
recommend("Isle of Man TT 2004 Review", 0)'주홍의 프로젝트 > 연습 프로젝트' 카테고리의 다른 글
| surprise 라이브러리 알고리즘 정리 (0) | 2022.07.04 |
|---|---|
| surprise 라이브러리 algorithm 정리 (0) | 2022.06.29 |
| 추천 시스템 정리 (0) | 2022.06.29 |
| Neural Network Embedding Recommendation System (kaggle) review (0) | 2022.06.23 |
| 사용자기반 협업 필터링 추천시스템 - 애니메이션 추천시스템 (1) | 2022.06.22 |




댓글