로지스틱 회귀(logistic regression)
회귀를 사용하여 데이터가 어떤 범주에 속할 확률이 0~1사이의 값으로 예측하고
예측 확률에 따라 가능성이 더 높은 범주에 속하는 것으로 분류해주는 지도학습 알고리즘이다.
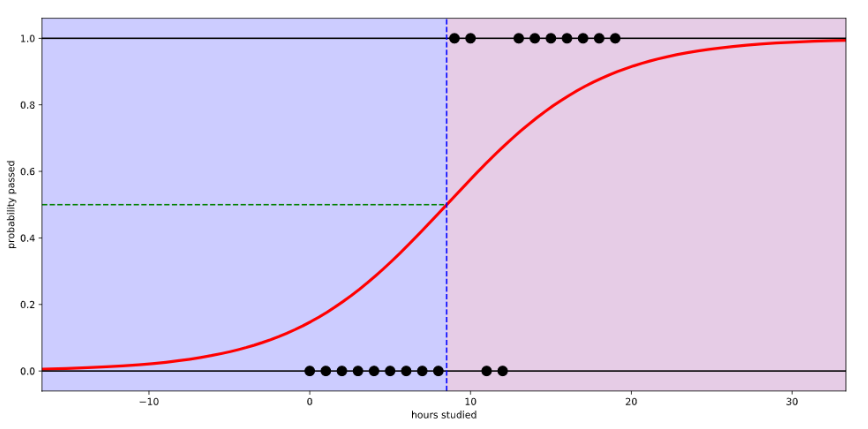
로지스틱 회귀는 참(1), 거짓(0)을 구분하는 S자 형태의 선을 그어주는 작업
시그모이드 함수(sigmoid function)

e = 2.71828... 자연상수라 불리는 무리수 = 파이와 비슷
구해야 하는 값 ax+b
a = 그래프의 경사도 (a값이 크면 경사도↑, a값이 작으면 경사도 ↓)
b = 그래프의 좌우 이동

코딩으로 확인하기
# 라이브러리
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
tf.__version__
# 데이터 만들기
data = [[2, 0], [4,0], [6, 0], [8,1], [10,1], [12,1], [14,1]]
x_data = [x_row[0] for x_row in data]
y_data = [y_row[1] for y_row in data]
# ax+b
# a 기울기값, b = y절편값 설정
# random seed는 random으로 생성한 결과가 항상 같은 value를 갖도록 하는 방법
a = tf.Variable(tf.random.normal([1], dtype=tf.float64, seed=0))
b = tf.Variable(tf.random.normal([1], dtype=tf.float64, seed=0))라이브러리와 데이터를 만든다.
사용 라이브러리 numpy, matplatlib, tensorflow
x_data = data 파일의 x 값 반복
y_data = data 파일의 y 값 반복
ax+b 구하기
a = 기울기 값, b = y절편 값
임의값 a, b 구하기
랜덤 데이터는 속성이 dtype = tf.float64인 1개의 값을 1~10개까지 생성하고 생성 값을 일정(seed)하게 한다.
# 시그모이드 함수 작성하기
y = 1/(1+ np.e**(a* x_data + b))
시그모이드 함수를 numpy 라이브러리를 이용해 작성
# 오차 = -평균(y*logh + (1-y)log(1-h)) 방정식 구현
# h = y, y_data = y
# treduce_mean() = 평균 구하기
loss = -tf.reduce_mean(np.array(y_data) * tf.log(y) + (1 - np.array(y_data)) * tf.log(1-y))오차 구하기
로그함수로 나타낸 a, b의 오차 함수를 방정식으로 나타내면
- reduce mean() 함수 : 평균구하기
# 학습률 지정, 오차 최소화하는 값 찾기(경사하강법)
learning_rate = 0.5
gradient_decent = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)학습률 learning_rate = 기존 지점에서 움직이는 값
- 기울기 2.0, 학습률 0.01 → 경사스탭 0.02
경사하강법(GradientDescentOptimizer)
- 미분의 기울기를 이용해 기울기가 0인점을 찾아가는 방법
#결과값 출력하기
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(60001):
sess.run(gradient_decent)
if i % 6000 ==0: # i = 6000번이 될 때마다 결과값 print
print("Epoch: %.f, loss = %.04f, 기울기 a = %.4f, y 절편 b = %.4f" % (i, sess.run(loss),sess.run(a),sess.run(b)))
모르는 용어
- seed = random seed는 random으로 생성한 결과가 항상 같은 value를 갖도록 하는 방법
- 학습률 learning_rate = 기존 지점에서 움직이는 값
- 기울기 2.0, 학습률 0.01 → 경사스탭 0.02
- reduce mean() 함수 : 평균구하기
- tf.global_variables_initializer() = 변수값 초기화
'머신러닝딥러닝 > 딥러닝' 카테고리의 다른 글
| 딥러닝(Deep Learning) #6 - 퍼셉트론 (0) | 2022.04.12 |
|---|---|
| 딥러닝(deeplearning) #5 - 다항 로지스틱 회귀(Multi_Logistic_Regression) (0) | 2022.04.12 |
| 딥러닝(deeplearning) #3 - 경사하강법 (0) | 2022.04.11 |
| 딥러닝(deeplearning) #2 - 선형회귀(MSE, RMSE) (0) | 2022.04.11 |
| 딥러닝(deeplearning) #1 - 폐암 수술 환자의 생존율 예측 (1) | 2022.04.11 |




댓글