mediapipe
pose estimation & classification


1. 사람 detect
2. Landmarks Detection

pose estimation + classification code (on colab)
라이브러리 설치 & 설정하기
# 라이브러리 설치
!pip install opencv-python mediapipe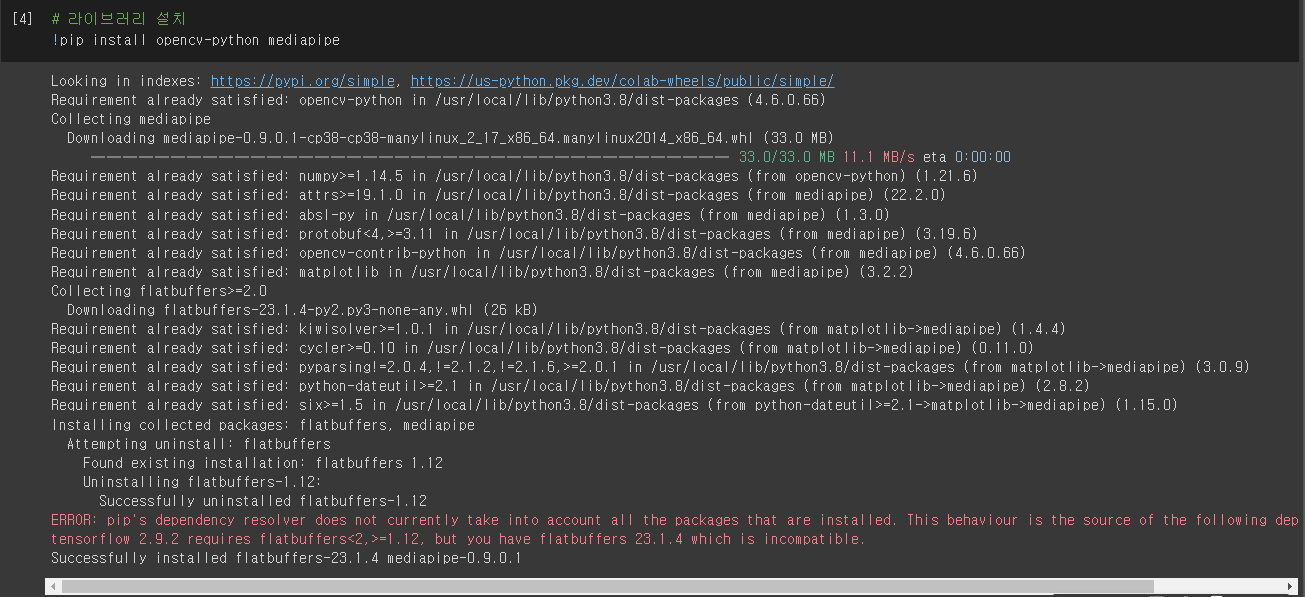
먼저 필요한 라이브러리인 opencv-python과 mediapipe를 설치한다.
!pip install opencv-python 띄우고 mediapipe를 입력하면 라이브러리 2개를 한번에 설치할 수 있다.
!pip install opencv-python
!pip install mediapipe
이렇게 설치해도 설치 결과는 똑같다.
# 라이브러리 설정
import math
import cv2
import numpy as np
from time import time
import mediapipe as mp
import matplotlib.pyplot as plt필요한 라이브러리를 불러와서 설정해준다.
math, cv2(=opencv), numpy, time, mediapipe, matplotlib이 필요하다.
image & video file에서 pose detect 수행하기
mediapipe의 mp.solutions.pose 구문을 이용하여 포즈 클래스를 초기화하고 mp.solutions.pose.Pose() 함수를 호출한다.
- static_image_mode(True, False)
True 설정일 경우, human_detector가 모든 이미지에서 호출된다. 비디오가 아닌 여러 이미지로 작업할 때 True를 주면되고 기본값은 False이다.
- min_detection_confidence(0.0, 1.0)
: human_detect_model의 predict가 정답으로 예측하는데 필요한 범위의 최소 감지 신뢰도를 말한다.
기본값은 0.5로 detector의 예측 신뢰도가 50% 이상인 경우 양성탐지로 간주한다.
-min_tracking_confidence([0.0, 1.0])
: 모델을 추적하는 pose landmark가 유효한 것으로 간주하기 위해 필요한 최소 추적 신뢰도를 말한다.
기본값은 0.5로 신뢰도가 설정값보다 작으면 검출기는 다음 image/frame에서 다시 호출되므로 값이 높으면 rubust해지지만, 수행 시간도 증가한다.
- model_complexity
: pose landmark model의 복잡도를 말한다. 3가지 모델을 선택할 수 있어 0, 1, 2 중 하나를 선택할 수 있다.
기본값은 1로 값이 높을 수록 결과는 정확하지만 수행 시간이 길어진다.
- smooth_landmark
노이즈를 줄이기 위해 프레임의 포즈 랜드마크가 필터링 됨, static_image_mode 작동 시에만 사용가능, 기본값 True
# Initializing mediapipe pose class.
# mediapipe pose class를 초기화 한다.
mp_pose = mp.solutions.pose
# Setting up the Pose function.
# pose detect function에 image detect=True, 최소감지신뢰도 = 0.3, 모델 복잡도 =2를 준다.
pose = mp_pose.Pose(static_image_mode=True, min_detection_confidence=0.3, model_complexity=2)
# Initializing mediapipe drawing class, useful for annotation.
# mediapipe의 drawing class를 초기화한다.
mp_drawing = mp.solutions.drawing_utils
이미지 읽어오기
cv2.imread()로 이미지를 읽어오고 matplotlib으로 이미지를 보여준다.
# 이미지 읽어오기
# 샘플 이미지를 cv2.imread()로 읽어온다
# Read an image from the specified path.
sample_img = cv2.imread('/content/drive/MyDrive/pose/sample.jpg')
# Specify a size of the figure.
plt.figure(figsize = [10, 10])
# Display the sample image, also convert BGR to RGB for display.
plt.title("Sample Image");plt.axis('off');plt.imshow(sample_img[:,:,::-1]);plt.show()
이미지 포즈 감지 수행하기
예시로 불러온 이미지를 machine learning pipeline인 mp.solutions.pose.Pose.process()에 전달한다.
이미지 파일은 RGB 색상 형식이므로 OPENCV의 cv2.COLOR_BGR2RGB 함수를 이용하여 POSE DETECT를 수행한다.
* opencv는 BGR 순서로 저장되고, matplotlib은 RGB 순서로 저장되기때문에 cv2.COLOR_BGR2RGB로 BGR을 RGB 값으로 변경한다.
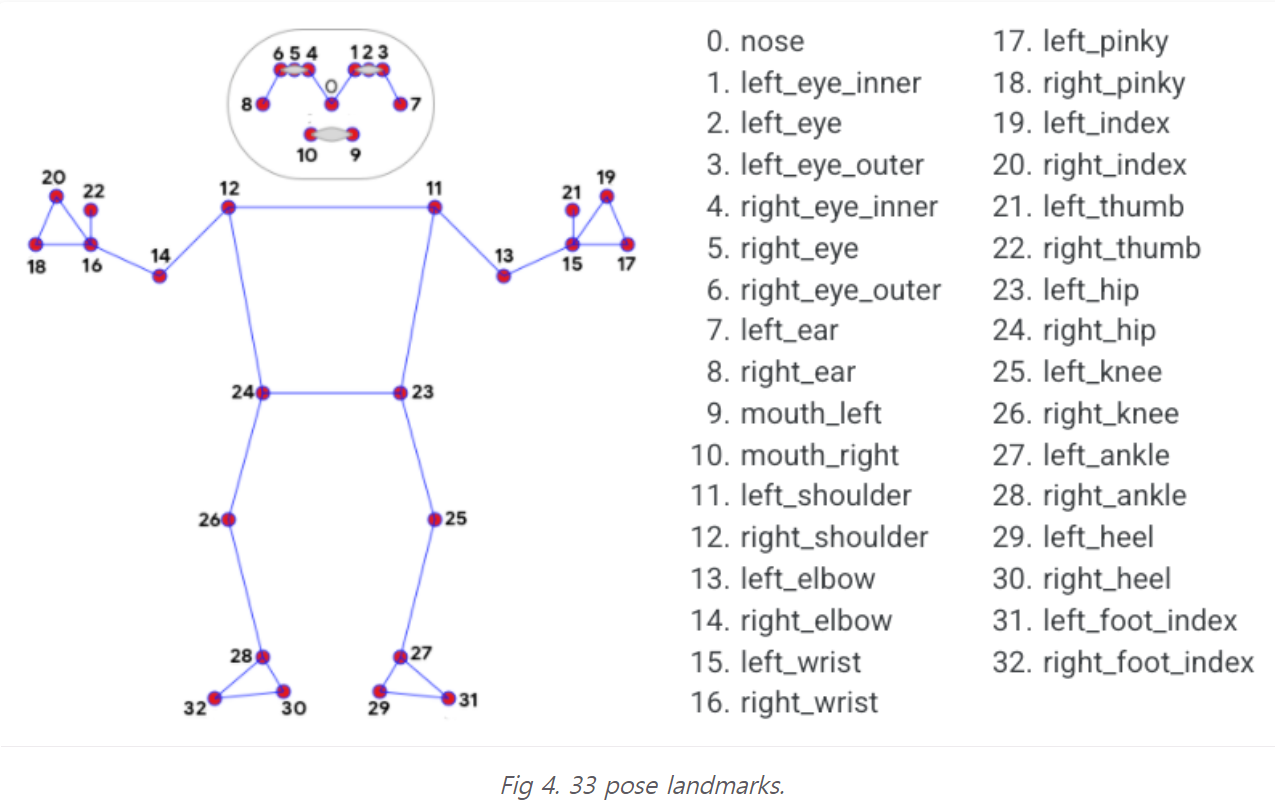
pose detect가 완료되었다면 사람의 신체 관절 위치를 나타내는 33개의 landmarks 목록을 가져온다.
각 랜드마크의 정보는 다음과 같다.
- x : 이미지 너비로 [0.0, 1.0]으로 정규화된 landmark x좌표이다.
- y : 이미지 높이로 [0.0, 1.0]으로 정규화된 landmark y좌표이다.
- z : x좌표와 거의 같은 축척으로 정규화된 z좌표이다. 엉덩이 중간점을 원점으로 하는 landmark의 깊이를 나타내므로 z 값이 작을수록 landmark가 카메라에 더 가까이 있다.
- visibility : image에서 landmark가 보일 가능성을 나타내는 0.0 ~ 1.0의 범위 값이다. 이미지에서 특정 관절을 가리거나 부분적으로 보일 경우 특정 관절을 표시할 지에 대한 여부를 결정하는 변수이다.
# pose detect 수행
# Perform pose detection after converting the image into RGB format.
results = pose.process(cv2.cvtColor(sample_img, cv2.COLOR_BGR2RGB))
# Check if any landmarks are found.
if results.pose_landmarks:
# Iterate two times as we only want to display first two landmarks.
for i in range(2):
# Display the found normalized landmarks.
print(f'{mp_pose.PoseLandmark(i).name}:\n{results.pose_landmarks.landmark[mp_pose.PoseLandmark(i).value]}')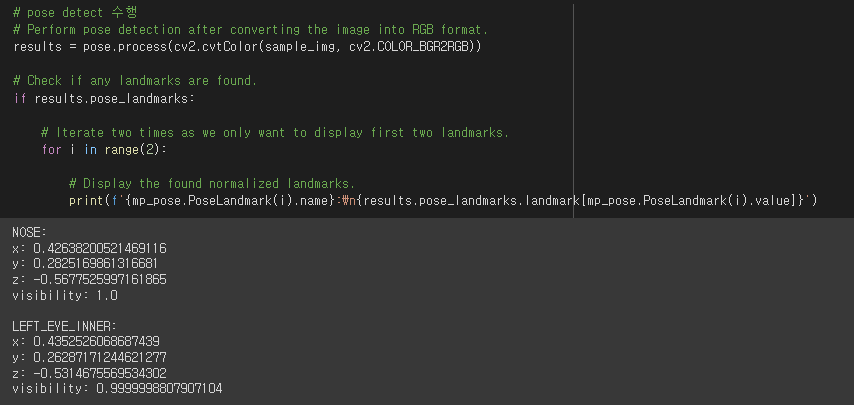
포즈 감지를 수행한 뒤에 코, 왼쪽눈 안쪽의 좌표를 나타내었다.
원본 이미지의 너비&높이를 이용하여 위에 나타낸 코와 왼쪽눈 안쪽의 정규화된 랜드마크를 원래 크기로 변환해준다.
# Retrieve the height and width of the sample image.
image_height, image_width, _ = sample_img.shape
# Check if any landmarks are found.
if results.pose_landmarks:
# Iterate two times as we only want to display first two landmark.
for i in range(2):
# Display the found landmarks after converting them into their original scale.
print(f'{mp_pose.PoseLandmark(i).name}:')
print(f'x: {results.pose_landmarks.landmark[mp_pose.PoseLandmark(i).value].x * image_width}')
print(f'y: {results.pose_landmarks.landmark[mp_pose.PoseLandmark(i).value].y * image_height}')
print(f'z: {results.pose_landmarks.landmark[mp_pose.PoseLandmark(i).value].z * image_width}')
print(f'visibility: {results.pose_landmarks.landmark[mp_pose.PoseLandmark(i).value].visibility}\n')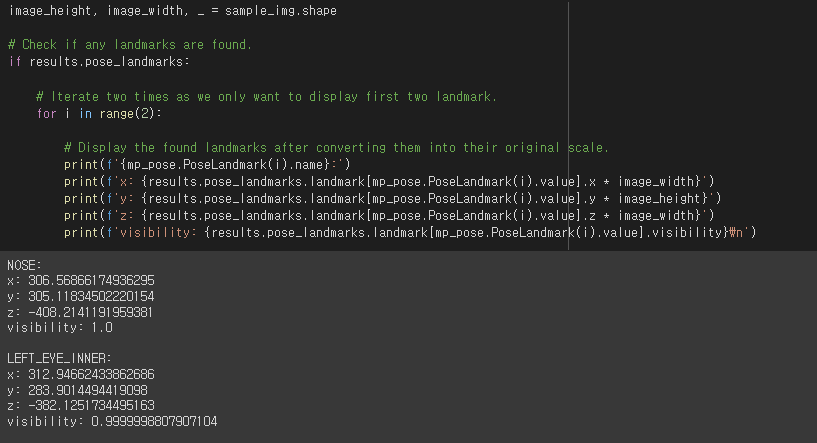
코와 왼쪽눈 안쪽의 좌표가 실제크기의 좌표로 변형된 결과를 확인할 수 있다.
# 랜드마크를 그릴 사진을 COPY한다.
img_copy = sample_img.copy()
# 랜드마크를 찾는다.
if results.pose_landmarks:
# sample image에 landmark를 그린다.
mp_drawing.draw_landmarks(image=img_copy, landmark_list=results.pose_landmarks, connections=mp_pose.POSE_CONNECTIONS)
# figure의 크기를 설정한다.
fig = plt.figure(figsize = [10, 10])
# landmark가 draw된 image를 보여주기 전에 BGR TO RGB를 위해 copy_image의 순서를 반대로 변형해준다.
plt.title("Output");plt.axis('off');plt.imshow(img_copy[:,:,::-1]);plt.show()
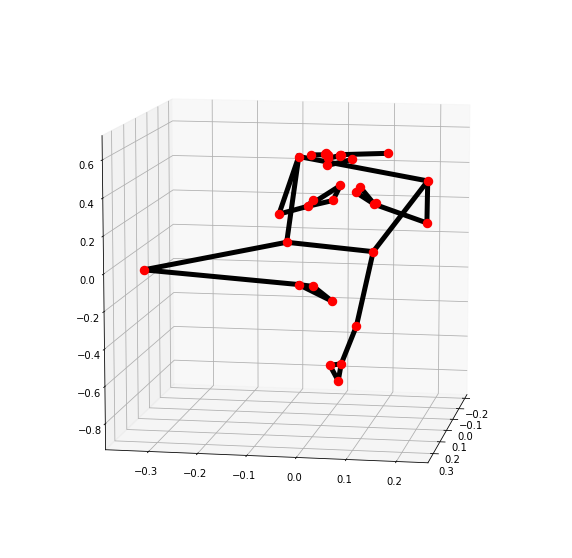
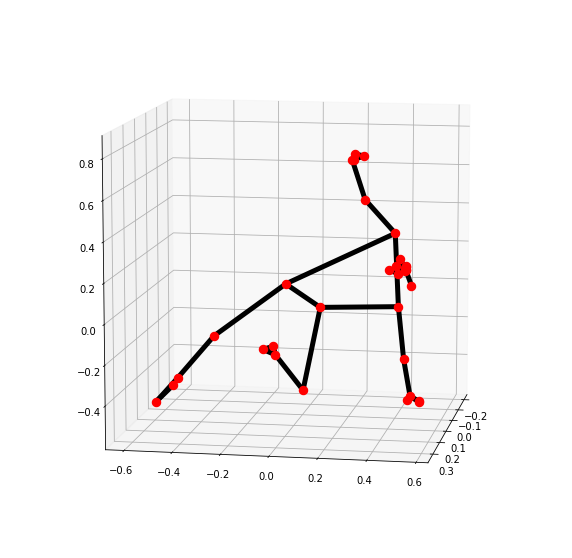
3차원으로 pose의 landmark를 확인할 수 있다.
# 3차원으로 pose의 landmark의 위치를 확인
mp_drawing.plot_landmarks(results.pose_world_landmarks, mp_pose.POSE_CONNECTIONS)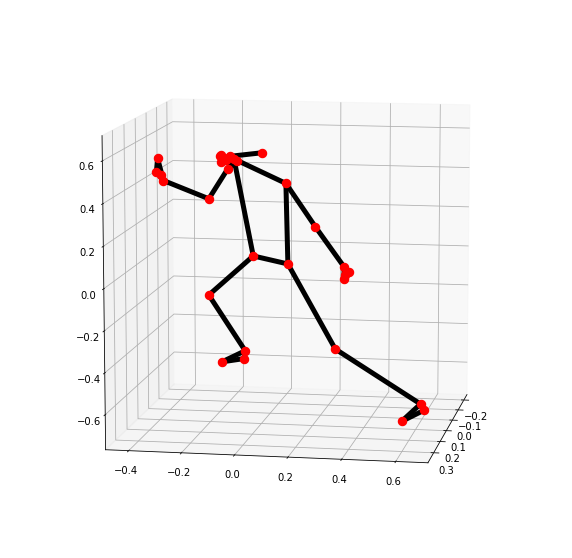
pose detection function 만들기
def detectPose(image, pose, display=True):
'''
This function performs pose detection on an image.
Args:
image: The input image with a prominent person whose pose landmarks needs to be detected.
pose: The pose setup function required to perform the pose detection.
display: A boolean value that is if set to true the function displays the original input image, the resultant image,
and the pose landmarks in 3D plot and returns nothing.
Returns:
output_image: The input image with the detected pose landmarks drawn.
landmarks: A list of detected landmarks converted into their original scale.
'''
# 예시이미지 copy하기
output_image = image.copy()
# 컬러 이미지 BGR TO RGB 변환
imageRGB = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# pose detection 수행
results = pose.process(imageRGB)
# input image의 너비&높이 탐색
height, width, _ = image.shape
# detection landmarks를 저장할 빈 list 초기화
landmarks = []
# landmark가 감지 되었는지 확인
if results.pose_landmarks:
# landmark 그리기
mp_drawing.draw_landmarks(image=output_image, landmark_list=results.pose_landmarks, connections=mp_pose.POSE_CONNECTIONS)
# 감지된 landmark 반복
for landmark in results.pose_landmarks.landmark:
# landmark를 list에 추가하기
landmarks.append((int(landmark.x * width), int(landmark.y * height), (landmark.z * width)))
# 오리지널 image와 pose detect된 image 비교
if display:
# 오리지널 & 아웃풋 이미지 그리기
plt.figure(figsize=[22,22])
plt.subplot(121);plt.imshow(image[:,:,::-1]);plt.title("Original Image");plt.axis('off');
plt.subplot(122);plt.imshow(output_image[:,:,::-1]);plt.title("Output Image");plt.axis('off');
# 3D 랜드마크 나타내기
mp_drawing.plot_landmarks(results.pose_world_landmarks, mp_pose.POSE_CONNECTIONS)
# 그렇지 않다면, output_image 와 landmark return한다
else:
return output_image, landmarks# pose detection function start
image = cv2.imread('/content/drive/MyDrive/pose/tree.jpg')
detectPose(image, pose, display=True)

실시간 웹캠에서 포즈감지하기
# Setup Pose function for video.
pose_video = mp_pose.Pose(static_image_mode=False, min_detection_confidence=0.5, model_complexity=1)
# Initialize the VideoCapture object to read from the webcam.
#video = cv2.VideoCapture(0)
# Initialize the VideoCapture object to read from a video stored in the disk.
video = cv2.VideoCapture('/content/drive/MyDrive/pose/yoga_3_pose.mp4')
# Initialize a variable to store the time of the previous frame.
time1 = 0
# Iterate until the video is accessed successfully.
while video.isOpened():
# Read a frame.
ok, frame = video.read()
# Check if frame is not read properly.
if not ok:
# Break the loop.
break
# Flip the frame horizontally for natural (selfie-view) visualization.
frame = cv2.flip(frame, 1)
# Get the width and height of the frame
frame_height, frame_width, _ = frame.shape
# Resize the frame while keeping the aspect ratio.
frame = cv2.resize(frame, (int(frame_width * (640 / frame_height)), 640))
# Perform Pose landmark detection.
frame, _ = detectPose(frame, pose_video, display=False)
# Set the time for this frame to the current time.
time2 = time()
# Check if the difference between the previous and this frame time > 0 to avoid division by zero.
if (time2 - time1) > 0:
# Calculate the number of frames per second.
frames_per_second = 1.0 / (time2 - time1)
# Write the calculated number of frames per second on the frame.
cv2.putText(frame, 'FPS: {}'.format(int(frames_per_second)), (10, 30),cv2.FONT_HERSHEY_PLAIN, 2, (0, 255, 0), 3)
# Update the previous frame time to this frame time.
# As this frame will become previous frame in next iteration.
time1 = time2
# Display the frame.
cv2.imshow('Pose Detection', frame)
# Wait until a key is pressed.
# Retreive the ASCII code of the key pressed
k = cv2.waitKey(1) & 0xFF
# Check if 'ESC' is pressed.
if(k == 27):
# Break the loop.
break
# Release the VideoCapture object.
video.release()
# Close the windows.
cv2.destroyAllWindows()
각도 휴리스틱을 이용한 포즈 분류
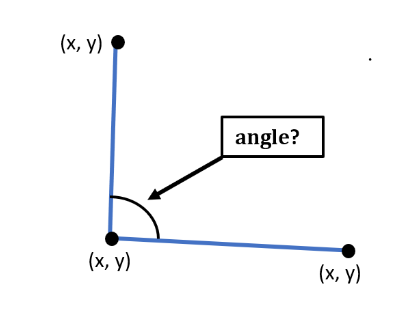
x, y, z 3개의 landmark 사이의 각도를 계산할 수 있는 함수를 생성한다.
첫 번째 landmark는 첫번째 라인 시작점으로 간주하고,
두 번째 landmark는 첫번째 라인 끝점과 두번째 라인 시작점으로 간주하고,
세 번째 landmark는 첫번째 라인의 끝점으로으로 간주된다.
임시 더미값으로 3개의 landmark를 생성해 계산해보자
# 앵글 계산 함수
def calculateAngle(landmark1, landmark2, landmark3):
# Get the required landmarks coordinates.
x1, y1, _ = landmark1
x2, y2, _ = landmark2
x3, y3, _ = landmark3
# Calculate the angle between the three points
angle = math.degrees(math.atan2(y3 - y2, x3 - x2) - math.atan2(y1 - y2, x1 - x2))
# Check if the angle is less than zero.
if angle < 0:
# Add 360 to the found angle.
angle += 360
# Return the calculated angle.
return angle
# 함수 실행
# Calculate the angle between the three landmarks.
angle = calculateAngle((558, 326, 0), (642, 333, 0), (718, 321, 0))
# Display the calculated angle.
print(f'The calculated angle is {angle}')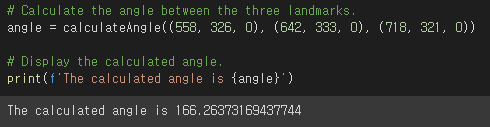
전사 포즈, T포즈, 나무포즈 3가지 요가 포즈를 관절의 각도 계산으로 분류할 수 있는 함수를 구현하자.
# 분류 함수
def classifyPose(landmarks, output_image, display=False):
# Initialize the label of the pose. It is not known at this stage.
label = 'Unknown Pose'
# Specify the color (Red) with which the label will be written on the image.
color = (0, 0, 255)
# Calculate the required angles.
#----------------------------------------------------------------------------------------------------------------
# Get the angle between the left shoulder, elbow and wrist points.
# 11번, 13번, 15번 landmark
# 왼쪽 어깨, 왼쪽 팔꿈치, 왼쪽 손목 landmark angle 값 계산
left_elbow_angle = calculateAngle(landmarks[mp_pose.PoseLandmark.LEFT_SHOULDER.value],
landmarks[mp_pose.PoseLandmark.LEFT_ELBOW.value],
landmarks[mp_pose.PoseLandmark.LEFT_WRIST.value])
# 12번, 14번, 16번 landmark
# 오른쪽 어깨, 오른쪽 팔꿈치, 오른쪽 손목 landmark angle 값 계산
right_elbow_angle = calculateAngle(landmarks[mp_pose.PoseLandmark.RIGHT_SHOULDER.value],
landmarks[mp_pose.PoseLandmark.RIGHT_ELBOW.value],
landmarks[mp_pose.PoseLandmark.RIGHT_WRIST.value])
# 13번, 15번, 23번 landmark
# 왼쪽 어깨, 왼쪽 팔꿈치, 왼쪽 엉덩이, landmark angle 값 계산
left_shoulder_angle = calculateAngle(landmarks[mp_pose.PoseLandmark.LEFT_ELBOW.value],
landmarks[mp_pose.PoseLandmark.LEFT_SHOULDER.value],
landmarks[mp_pose.PoseLandmark.LEFT_HIP.value])
# 12번, 14번, 24번 landmark
# 오른쪽 어깨, 오른쪽 팔꿈치, 오른쪽 엉덩이 landmark angle 값 계산
right_shoulder_angle = calculateAngle(landmarks[mp_pose.PoseLandmark.RIGHT_HIP.value],
landmarks[mp_pose.PoseLandmark.RIGHT_SHOULDER.value],
landmarks[mp_pose.PoseLandmark.RIGHT_ELBOW.value])
# 23번, 25번, 27번 landmark
# 왼쪽 엉덩이, 왼쪽 무릎, 왼쪽 발목 landmark angle 값 계산
left_knee_angle = calculateAngle(landmarks[mp_pose.PoseLandmark.LEFT_HIP.value],
landmarks[mp_pose.PoseLandmark.LEFT_KNEE.value],
landmarks[mp_pose.PoseLandmark.LEFT_ANKLE.value])
# 24번, 26번, 28번 landmark
# 오른쪽 엉덩이, 오른쪽 무릎, 오른쪽 발목 landmark angle 값 계산
right_knee_angle = calculateAngle(landmarks[mp_pose.PoseLandmark.RIGHT_HIP.value],
landmarks[mp_pose.PoseLandmark.RIGHT_KNEE.value],
landmarks[mp_pose.PoseLandmark.RIGHT_ANKLE.value])
#----------------------------------------------------------------------------------------------------------------
# 전사포즈 vs T포즈 비교
# 두 포즈 모두 양팔을 곧게 펴고 어깨를 일정한 각도로 유지한다.
# 전사 포즈는 다리를 벌리지만, T포즈는 다리를 일자리 쭉 펴고 있다는 점 이 다르다
# 양팔을 모두 곧게 펴고 있는지 체크한다
# 왼쪽, 오른쪽 팔, 어깨, 팔꿈치의 각도가 165 ~ 195도 사이에 위치하는지 확인한다.
if left_elbow_angle > 165 and left_elbow_angle < 195 and right_elbow_angle > 165 and right_elbow_angle < 195:
# 양 팔의 팔꿈치, 어깨, 엉덩이까지 각도가 80 ~ 110도 사이에 위치하는지 확인한다.
if left_shoulder_angle > 80 and left_shoulder_angle < 110 and right_shoulder_angle > 80 and right_shoulder_angle < 110:
#----------------------------------------------------------------------------------------------------------------
# 전사포즈인지 확인
#----------------------------------------------------------------------------------------------------------------
# 한쪽다리를 곧게 뻗고 있는지 확인한다.
if left_knee_angle > 165 and left_knee_angle < 195 or right_knee_angle > 165 and right_knee_angle < 195:
# 한쪽다리를 곧게 뻗고 있다면
# 다른쪽 다리를 90도 ~ 120 사이로 굽히고 있는지 확인한다.
if left_knee_angle > 90 and left_knee_angle < 120 or right_knee_angle > 90 and right_knee_angle < 120:
# 양팔을 일자로 펼치고, 한쪽 다리는 곧게, 다른쪽 다리는 굽히고 있다면
# 전사자세로 분류한다.
label = 'Warrior II Pose'
#----------------------------------------------------------------------------------------------------------------
# T포즈인지 확인
#----------------------------------------------------------------------------------------------------------------
# 양 다리 모두 곧게 뻗고 있는지 확인한다.
if left_knee_angle > 160 and left_knee_angle < 195 and right_knee_angle > 160 and right_knee_angle < 195:
# 양팔을 일자로 펼치고, 양쪽다리 모두 일자로 펴고 있다면
# T포즈로 분류한다
label = 'T Pose'
#----------------------------------------------------------------------------------------------------------------
# 트리포즈
#----------------------------------------------------------------------------------------------------------------
# 양발 중 한 발을 곧게 펴고 있는지 확인
if left_knee_angle > 165 and left_knee_angle < 195 or right_knee_angle > 165 and right_knee_angle < 195:
# 양발 중 다른 한 발이 왼쪽이라면 315 ~ 335, 오른쪽이라면 25 ~ 45로 구부러져 있는지
if left_knee_angle > 315 and left_knee_angle < 335 or right_knee_angle > 25 and right_knee_angle < 45:
# Specify the label of the pose that is tree pose.
label = 'Tree Pose'
#----------------------------------------------------------------------------------------------------------------
# 포즈 분류가 잘 되었는지 확인
if label != 'Unknown Pose':
color = (0, 255, 0)
# 분류되지 않은 자세라면 Unkwown Pose로 왼쪽 상단에 연두색으로 text 입력
cv2.putText(output_image, label, (10, 30),cv2.FONT_HERSHEY_PLAIN, 2, color, 2)
# 결과 이미지 보여주기 Check if the resultant image is specified to be displayed.
if display:
# 결과 이미지를 BGR TO RGB로 matplotlib을 이용해 꺼내준다.
plt.figure(figsize=[10,10])
plt.imshow(output_image[:,:,::-1]);plt.title("Output Image");plt.axis('off');
else:
# 결과 이미지랑 표시될 label을 return 한다
return output_image, label입력된 image나 video 등 콘텐츠에 있는 사람들을 detect하고 관절의 위치를 파악하여 skeleton을 뽑아낸다.
해당 skeleton은 33개의 관절로 이루어져있고
3개의 skeleton landmark는 하나의 angle이 되어 각도별 포즈에 따르 estimation해주게 된다.
모든 자세마다 기준이 될 skeleton angle 3개의 점들을 정하고 각 각도에 맞는다면 T포즈, 전사포즈 등 다양한 pose에 따라 classify할 수 있다.


예를 들어, 전사 포즈를 취하고 있다면 양쪽 팔꿈치에서 약 180도, 양쪽 어깨의 각도 약 90도로 상체를 유지해야한다.
하체는 한쪽 무릎에서 약 180도 각도를, 다른 무릎에서 약 90도 각도를 유지하면 전사 자세라고 분류한다.
실시간 웹캠으로 pose 분류하기
# Setup Pose function for video.
pose_video = mp_pose.Pose(static_image_mode=False, min_detection_confidence=0.5, model_complexity=1)
# Initialize the VideoCapture object to read from the webcam.
camera_video = cv2.VideoCapture(0)
# Initialize a resizable window.
cv2.namedWindow('Pose Classification', cv2.WINDOW_NORMAL)
# Iterate until the webcam is accessed successfully.
while camera_video.isOpened():
# Read a frame.
ok, frame = camera_video.read()
# Check if frame is not read properly.
if not ok:
# Continue to the next iteration to read the next frame and ignore the empty camera frame.
continue
# Flip the frame horizontally for natural (selfie-view) visualization.
frame = cv2.flip(frame, 1)
# Get the width and height of the frame
frame_height, frame_width, _ = frame.shape
# Resize the frame while keeping the aspect ratio.
frame = cv2.resize(frame, (int(frame_width * (640 / frame_height)), 640))
# Perform Pose landmark detection.
frame, landmarks = detectPose(frame, pose_video, display=False)
# Check if the landmarks are detected.
if landmarks:
# Perform the Pose Classification.
frame, _ = classifyPose(landmarks, frame, display=False)
# Display the frame.
cv2.imshow('Pose Classification', frame)
# Wait until a key is pressed.
# Retreive the ASCII code of the key pressed
k = cv2.waitKey(1) & 0xFF
# Check if 'ESC' is pressed.
if(k == 27):
# Break the loop.
break
# Release the VideoCapture object and close the windows.
camera_video.release()
cv2.destroyAllWindows()

참고영상
https://www.youtube.com/watch?v=aySurynUNAw
'머신러닝딥러닝 > detection' 카테고리의 다른 글
| mediapipe - face detect & pose estimation 동시 실행하기 (0) | 2023.01.20 |
|---|---|
| mediapipe face detect - webcam 실시간 실행하기 (0) | 2023.01.19 |
| ubuntu 18.04 webcam 설치 및 사용하기 (2) | 2023.01.16 |
| 구글 AI프레임워크 MediaPipe(미디어파이프)란? (0) | 2023.01.13 |
| linux ubuntu 18.04에 mediapipe build 실행하기 (0) | 2023.01.13 |




댓글