콘텐츠기반 추천시스템 Content based filtering
콘텐츠기반 필터링은 사용자가 특정 상품을 선호하는 경우,
사용자 선호도를 기반으로 유사한 콘텐츠를 제안하는 추천시스템.
추천콘텐츠 = '영화'
특정 항목(태그) = 장르, 감독, 배우, 줄거리, 개봉년도, 평점 등
추천방식 = 특정 항목(태그)를 좋아하면, 비슷한 유사도를 가진 콘텐츠 추천

TF-IDF
단어사용비도를 이용한 단어마다 중요정도에 가중치를 주는 방법
TF = 특정문서(d)에서 특정단어(t)가 등장하는 횟수,
IDF = dt(t가 등장한 문서의 수)에 반비례하는 수
특정영화 정보, 유사도 찾아내기
유사도 분석 = Cosine similarity
장점
- 사용자가 선호한 특정정보만으로 콘텐츠 추천 가능
- 추천할 수 있는 아이템이 많다.(특정정보 묶음에 따라 인기/비인기/생소한 분야 등 제약없이 추천가능)
단점
- 단순 특정 단어만 특정하여 추천해 줌
- 다른 사용자의 선호도를 참고하지 않음
- content 단어 순서에 따른 유사도 계산 = 유사도 정확성이 떨어짐
최근접이웃 기반 협업필터링(nearest neighbor based collaborative filltering)
협업필터링(collaborative filtering)의 종류중 하나.
사용자의 평점, 구매이력, 행동양식을 기반으로 제안하는 추천시스템
사용자가 평가하지 않은 상품을 예측하는 것이 목표
데이터 : csv 파일 기본적인 행,렬 변환(사용자 = row, 영화 = columns, 내용 = 평점)
아이템기반 협업필터링 추천시스템 : 아이템 유사도 기준으로 추천하는 시스템
아이템-사용자 행렬
- 아이템간 유사도가 높을 때, 비슷한 평가를 한 사용자에게 추천하는 방식
- 아이템 유사도가 우선
사용자기반 협업필터링 추천시스템 : 비슷한 사용자들이 'a'를 사용했다.
사용자-아이템(영화) 행렬
- 사용자간의 유사도가 높을 때, 평가가 좋은 아이템을 추천하는 방식
- 사용자 유사도 우선
Surprise(SVD + KNN) 추천시스템
Python 기반 추천시스템 구축 전용패키지
data = [user_id, item_id, score]로 설정하고 3개의 컬럼만 사용가능한 특징이 있다.
SVD : 행렬 분해를 통한 잠재 요인 협업필터링을 위한 SVD 알고리즘
KNNi: 최근접 이웃 협업 필터링
BaselineOnly : 사용자 Bias, 아이템 Bias 고려한 SGD 베이라인 알고리즘
교차검증(cross_validate())
인자로 알고리즘 객체, 데이터, 성능 평가 방법, 폴드 데이터 세트 개수(cv)를 입력
출력결과, 폴드별 성능 평가 수치, 전체 폴드의 평균 성능 평가 수치를 보여줌.
하이퍼 파라미터 튜닝
최적 구동수와 최적 인수 구하기
GridSearchCV -> 너무 오래걸림
최근접이웃 협업 필터링(KNN)
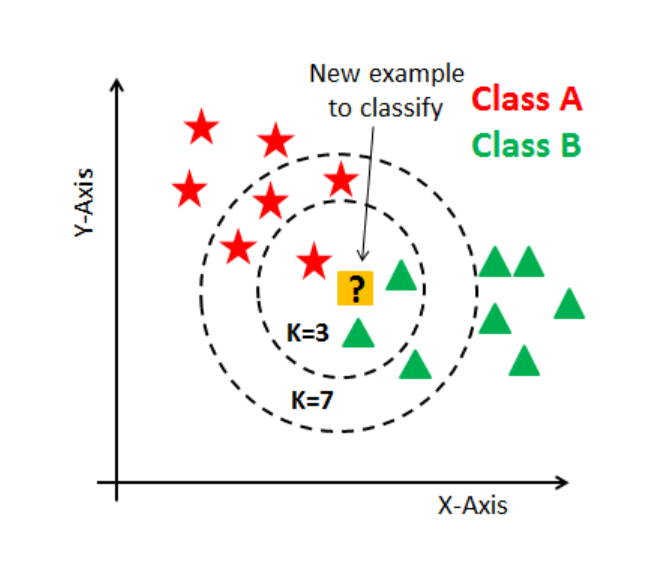
개인에 특화된 영화추천 알고리즘
- 관람한 영화에 대한 평점 데이터
- 관람하지 않은 영화에 대한 아이템 유사도 및 예측평점
- 유사도와 예측평점이 높다면 추천
댓글