추천 시스템 정리
③추천 시스템
사용자가 관심을 가질만한 아이템, 정보를 제공해주는 시스템입니다.
명시적데이터, 암시적 데이터를 이용하여 사용자의 취향, 욕구, 니즈에 맞는 선택지를 제공하는 시스템입니다.
사용데이터
| 명시적 데이터(Explicit data = Explicit Feedback) | 암시적 데이터(Implicit data = Implicit Feedback) |
| 아이템에 대한 사용자의 선호도를 직접적으로 알 수 있는 data - 사용자 평가 데이터 ex) 1점 ~ 5점, 별점 - 사용자 긍정 / 부정 데이터(좋아요, 보통, 싫어요) - 직관적, 사용자 직접평가, 데이터 수집이 힘듬 |
사용자의 아이템 소비를 기록한 데이터 - 평가, 긍정/부정의 구분이 없음 - 직관적으로 알 수 없는 경우에 사용 - 최근 추천 알고리즘들은 암시적 피드백을 이용해 구현 ex ) 뉴스 클릭수, 검색기록, 장바구니, 구매내역 등 |
1. Content_based Filtering
사용자가 선호하는 아이템 정보를 기반으로 유사한 아이템을 추천하는 시스템입니다.
process
① 아이템 특징 추출(제목, 장르, 카테고리, 배우, 출시연도 등) 후 벡터 변환
② 알고리즘을 이용해 사용자가 좋아하는 상품B와 유사한 상품선별
③ 상품 중 평점 이 높은 아이템을 추천
장점
- 다른 사용자에 대한 데이터가 필요하지 않고, 콘텐츠 데이터로만 추천이 가능하다는 점
- 단순히 평점이 높거나, 유명한 아이템이 아니라 해당 유저의 선호도에 따른 틈새 상품을 추천할 수 있다는 점
단점
- 해당 사용자의 선호 데이터를 모르면 평가가 힘들 수 있다는 점
- 해당 사용자에게 특정된 아이템들만을 추천하여 다양한 추천이 불가능하다는 점
- 필터 버블(Filter bubble) : 개인 추천에 따른 정보편식현상, 사용자가 제한된 주제/관점의 콘텐츠만 소비할 수 있다는 점
유사도

1) 코사인 유사도(Cosine Similariry)
2) 피어슨 유사도(Pearson Similarity)
2. Collaborative Filtering(item_based CF / user_based CF)
Collaborative Filtering(협업 필터링)은 많은 유저들의 정보를 기반으로 하여 예측하는 기술입니다.
'대상 유저와 비슷한 성향의 고객들은 다른 상품에 대해서도 선호도가 비슷할 것이다.'는 가정하에 비슷한 사용자들이 사용한 아이템을 추천하는 방식의 추천시스템입니다.
- scikit-learn library : cosine similarity
- surprise library : Matrix Factorization(SVD())이용
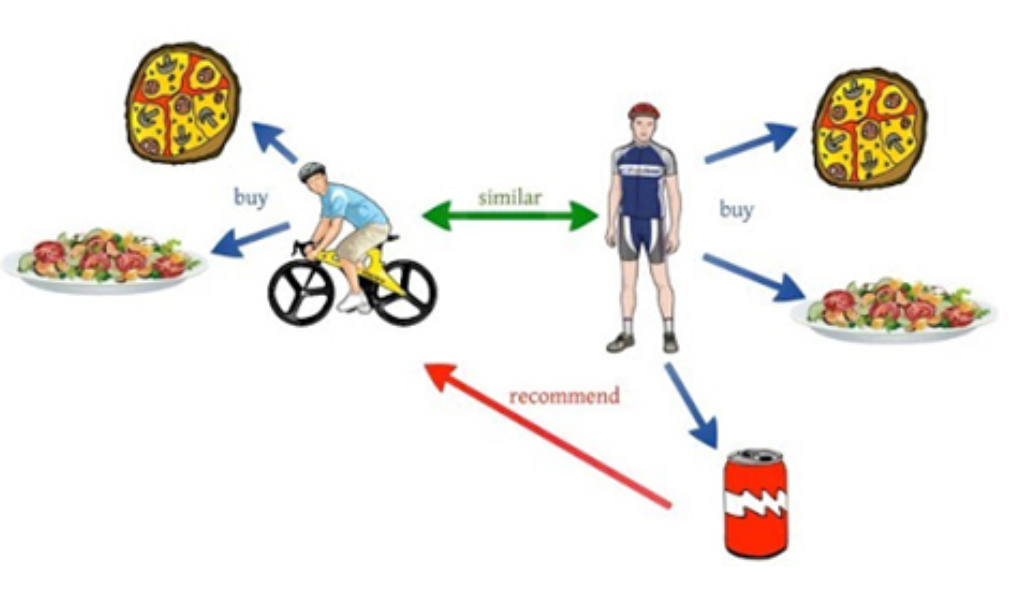
1) user_based CF(=anime_userbased)

사용자간 유사도를 추정했을 때,
JUNO와 비슷한 유저가 먹은 음식 중 JUNO가 먹지 않은 파스타를 추천합니다.
2) item_based CF

아이템 기반 협업 필터링은 아이템간 유사도를 계산합니다.
피자와 치킨의 유사하다고 추정되었을 때, 아직 피자를 먹지 않은 user3에게 치킨을 추천합니다.
3. Hybrid Filtering(content_based Filtering + Collaborative Filtering)

콘텐츠 기반 필터링과 협업 필터링을 결합한 모델
Hybrid Filtering algorIthm - surprise library
svdpp(SVD++) SVD의 확장형 알고리즘으로 implicit data에 대한 특이값 분해가 가능함.
-> implicit data에 사용이 가능하다는 점만 확인, 적용 여부.. ?
4. Deeplearning Hybrid recommendation - keras(embedding)
# Create user- & movie-id mapping
user_id_mapping = {id:i for i, id in enumerate(df['User'].unique())}
movie_id_mapping = {id:i for i, id in enumerate(df['Movie'].unique())}
# Use mapping to get better ids
df['User'] = df['User'].map(user_id_mapping)
df['Movie'] = df['Movie'].map(movie_id_mapping)
##### Combine both datasets to get movies with metadata
# Preprocess metadata
tmp_metadata = movie_metadata.copy()
tmp_metadata.index = tmp_metadata.index.str.lower()
# Preprocess titles
tmp_titles = movie_titles.drop('Year', axis=1).copy()
tmp_titles = tmp_titles.reset_index().set_index('Name')
tmp_titles.index = tmp_titles.index.str.lower()
# Combine titles and metadata
df_id_descriptions = tmp_titles.join(tmp_metadata).dropna().set_index('Id')
df_id_descriptions['overview'] = df_id_descriptions['overview'].str.lower()
del tmp_metadata,tmp_titles
# Filter all ratings with metadata
df_hybrid = df.drop('Date', axis=1).set_index('Movie').join(df_id_descriptions).dropna().drop('overview', axis=1).reset_index().rename({'index':'Movie'}, axis=1)
# Split train- & testset
n = 100000
df_hybrid = df_hybrid.sample(frac=1).reset_index(drop=True)
df_hybrid_train = df_hybrid[:1500000]
df_hybrid_test = df_hybrid[-n:]
# Create tf-idf matrix for text comparison
tfidf = TfidfVectorizer(stop_words='english')
tfidf_hybrid = tfidf.fit_transform(df_id_descriptions['overview'])
# Get mapping from movie-ids to indices in tfidf-matrix
mapping = {id:i for i, id in enumerate(df_id_descriptions.index)}
train_tfidf = []
# Iterate over all movie-ids and save the tfidf-vector
for id in df_hybrid_train['Movie'].values:
index = mapping[id]
train_tfidf.append(tfidf_hybrid[index])
test_tfidf = []
# Iterate over all movie-ids and save the tfidf-vector
for id in df_hybrid_test['Movie'].values:
index = mapping[id]
test_tfidf.append(tfidf_hybrid[index])
# Stack the sparse matrices
train_tfidf = vstack(train_tfidf)
test_tfidf = vstack(test_tfidf)
##### Setup the network
# Network variables
user_embed = 10
movie_embed = 10
# Create two input layers
user_id_input = Input(shape=[1], name='user')
movie_id_input = Input(shape=[1], name='movie')
tfidf_input = Input(shape=[24144], name='tfidf', sparse=True)
# Create separate embeddings for users and movies
user_embedding = Embedding(output_dim=user_embed,
input_dim=len(user_id_mapping),
input_length=1,
name='user_embedding')(user_id_input)
movie_embedding = Embedding(output_dim=movie_embed,
input_dim=len(movie_id_mapping),
input_length=1,
name='movie_embedding')(movie_id_input)
# Dimensionality reduction with Dense layers
tfidf_vectors = Dense(128, activation='relu')(tfidf_input)
tfidf_vectors = Dense(32, activation='relu')(tfidf_vectors)
# Reshape both embedding layers
user_vectors = Reshape([user_embed])(user_embedding)
movie_vectors = Reshape([movie_embed])(movie_embedding)
# Concatenate all layers into one vector
both = Concatenate()([user_vectors, movie_vectors, tfidf_vectors])
# Add dense layers for combinations and scalar output
dense = Dense(512, activation='relu')(both)
dense = Dropout(0.2)(dense)
output = Dense(1)(dense)
# Create and compile model
model = Model(inputs=[user_id_input, movie_id_input, tfidf_input], outputs=output)
model.compile(loss='mse', optimizer='adam')
model.summary()
# Train and test the network
model.fit([df_hybrid_train['User'], df_hybrid_train['Movie'], train_tfidf],
df_hybrid_train['Rating'],
batch_size=1024,
epochs=2,
validation_split=0.1,
shuffle=True)
y_pred = model.predict([df_hybrid_test['User'], df_hybrid_test['Movie'], test_tfidf])
y_true = df_hybrid_test['Rating'].values
rmse = np.sqrt(mean_squared_error(y_pred=y_pred, y_true=y_true))
print('\n\nTesting Result With Keras Hybrid Deep Learning: {:.4f} RMSE'.format(rmse))추천시스템 단점 : cold start
새로운 유저가 유입되었을 때, 정보의 부족으로 제대로된 추천이 불가능 할 경우의 문제
해결법 : lightfm