unsplash image crawling python 이미지 사이트 크롤링 방법
web Crawling 웹 크롤링이란?
웹 크롤링 Web Crawing이란 웹 페이지에서 정보를 수집할 수 있는 자동화된 프로세스입니다.
웹 크롤링 기술을 이용해서 검색엔진에서 데이터 분석 및 정보 수집등 다양한 목적으로 데이터를 수집하고 사용합니다.
- 크롤러(Crawler)
웹 크롤링의 핵심적인 역할로 웹 페이지를 방문했을 때, 방문 페이지의 링크를 추출해내는 프로그램입니다.
크롤러(Crawler)를 통해 여러 웹 페이지를 자동으로 접근할 수 있습니다.
- 스크래퍼(Scraper)
스크래퍼(Scraper)는 웹 크롤러가 방문한 웹 페이지 링크에서 필요한 데이터를 추출하는 프로그램입니다.
일반적으로 HTML 문서를 분석하여 원하는 정보를 추출하는데 사용합니다.
Web Crawling의 과정 및 원리
1. 크롤러
크롤러를 통해 데이터가 필요한 웹 페이지를 방문하고 그 안의 링크를 추출하고, 스크래퍼를 이용해 크롤러가 방문한 웹 페이지에서 데이터를 추출한다.
2. HTTP 요청
크롤러는 HTTP 또는 HTTPS 프로토콜을 사용하여 웹 서버에 정보를 요청합니다.
이 요청에는 특정한 헤더 및 매개변수가 포함될 수 있습니다.
3. 웹 페이지 다운로드
서버는 크롤러의 요청에 응답하여 웹페이지의 내용과 구조가 담겨있는 웹 페이지의 HTML 문서를 제공합니다.
4. HTML Parsing
BeautifulSoup, lxml 등 파싱 라이브러리를 이용해 HTML 웹페이지에서 필요한 데이터를 추출합니다.
5. 데이터 추출 및 저장
추출된 데이터는 텍스트, 이미지 url, 링크 등 다양한 형태의 데이터를 추출한다.
해당 데이터를 이용하여 csv 파일, image 파일 등으로 저장하여 활용할 수 있습니다.
저장된 데이터 파일을 이용해 DB를 구축하거나 사용자가 필요한 용도로 사용할 수 있습니다.
웹 크롤링 시 주의사항 및 윤리사항
웹 사이트의 이용 약관을 따르고, 서버에 부담을 주지 않도록 적절한 요청주기를 설정하는 게 좋습니다.
크롤링한 데이터의 사용은 법적인 제한 사항과 웹 사이트의 이용 약관을 준수해야 합니다.
unsplash image crawlier
사진을 무료로 제공하고 있는 퍼블릭 도메인인 unsplash 사이트에서 이미지를 검색하고,
검색결과로 추출된 이미지들을 크롤링 할 수 있는 코드를 이용해서 크롤링을 진행해보았습니다.
https://github.com/ritik48/unsplash-image-downloader
GitHub - ritik48/unsplash-image-downloader
Contribute to ritik48/unsplash-image-downloader development by creating an account on GitHub.
github.com
main.py와 image_downloader.py 코드를 같은 폴더에 저장하고 main.py 폴더를 실행하면 웹 크롤링이 가능합니다.

코드를 실행하면 unsplash 사이트에 무슨 키워드를 검색할지 입력하는 검색창이 터미널에 올라옵니다.
해당 질문에 검색할 이미지를 입력해줍니다.

"soccer" 라는 키워드로 검색된 이미지가 총 4432개의 이미지 파일이 있고, 몇개를 다운로드 할 거냐는 질문이 나옵니다. 적당히 20개의 파일을 다운로드 받는다고 입력했습니다.
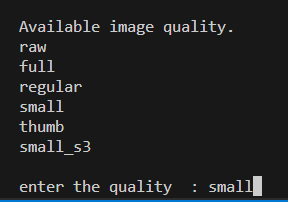
unsplash는 사진을 다운로드 받을 때, 사진의 퀄리티를 지정할 수 있는데 small로 지정해줍니다.
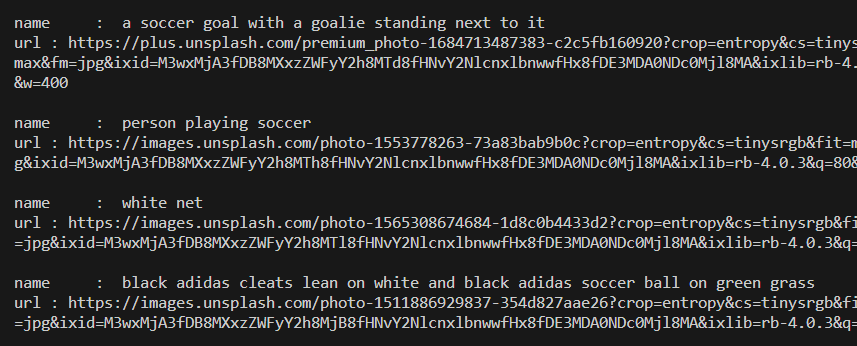

먼저 image 파일에 대한 url 크롤링이 진행되는데, image 파일 이름과 url이 크롤링 되는 모습을 확인할 수 있습니다.
실제로 url을 인터넷 주소창에 입력하면 검은색 바탕에 띄워진 사진을 확인할 수 있었습니다.
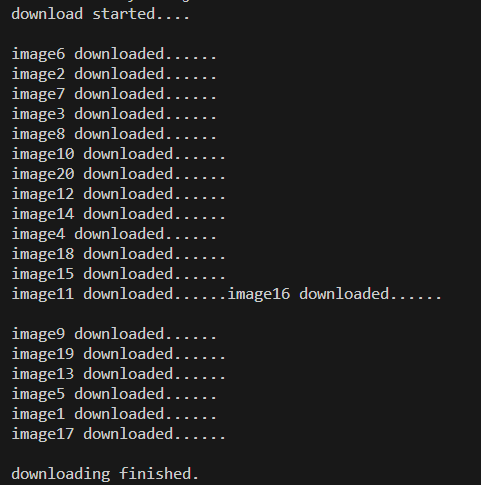
download started...이라는 문구가 뜨고 실제 이미지가 small image 사이즈로 다운로드됩니다.
다운로드 폴더는 해당 코드가 있는 폴더에 자동으로 검색한 키워드의 폴더가 생성되고, 디렉토리에 이미지로 저장됩니다.
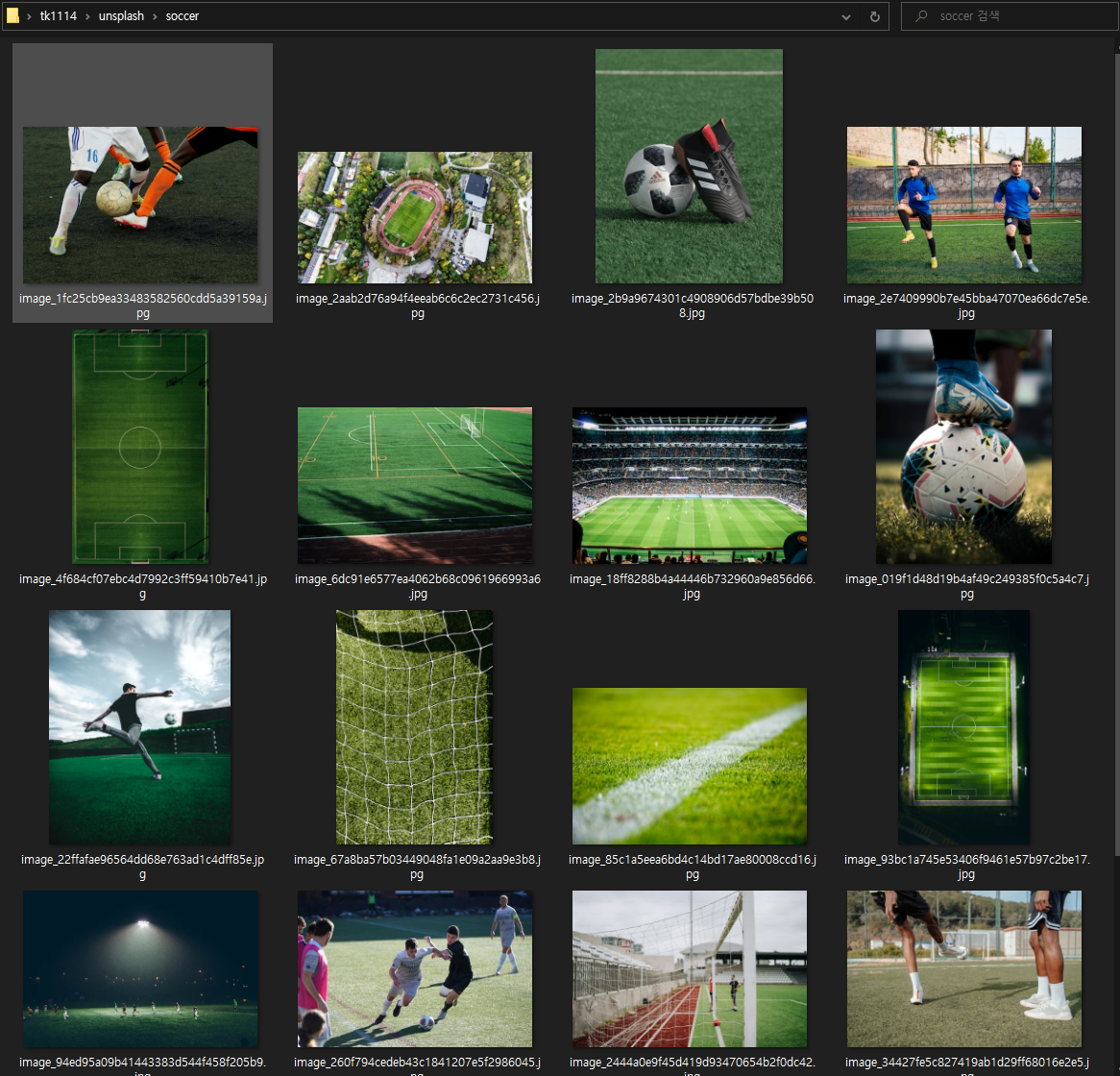
실제로 soccer 키워드가 unsplash에서 검색되어 soccer 관련 사진 20개가 저장된 모습을 확인할 수 있었습니다.
main.py
import requests
import os
import time
import image_downloader
class UnsplashImageDownloader:
def __init__(self, query):
self.querystring = {"query": f"{query}", "per_page": "20"}
self.headers = {"cookie": "ugid=aacdcdf3a2acebee349c2e196e621b975571725"}
self.url = "https://unsplash.com/napi/search/photos"
self.query = query
def get_total_images(self):
with requests.request("GET", self.url, headers=self.headers, params=self.querystring) as rs:
json_data = rs.json()
return json_data["total"]
def get_links(self, pages_, quality_):
all_links = []
for page in range(1, int(pages_) + 1):
self.querystring["page"] = f"{page}"
response = requests.request("GET", self.url, headers=self.headers, params=self.querystring)
response_json = response.json()
all_data = response_json["results"]
for data in all_data:
name = None
try:
name = data["sponsorship"]["tagline"]
except:
pass
if not name:
try:
name = data['alt_description']
except:
pass
if not name:
name = data['description']
try:
image_urls = data["urls"]
required_link = image_urls[quality_]
print("name : ", name)
print(f"url : {required_link}\n")
all_links.append(required_link)
except:
pass
return all_links
if __name__ == '__main__':
search = input("What you want to search for ?")
folder = f"unsplash/{search}"
if not os.path.exists(folder):
os.mkdir(folder)
unsplash = UnsplashImageDownloader(search)
total_image = unsplash.get_total_images()
print("\ntotal images available : ", total_image)
if total_image == 0:
print("sorry, no image available for this search")
exit()
number_of_images = int(input("enter number of images you want to download : "))
if number_of_images == 0 or number_of_images > total_image:
print("not a valid number")
exit()
pages = float(number_of_images / 20)
if pages != int(pages):
pages = int(pages) + 1
print("\nAvailable image quality.\nraw\nfull\nregular\nsmall\nthumb\nsmall_s3\n")
quality = input("enter the quality : ")
image_links = unsplash.get_links(pages, quality)
start = time.time()
print("download started....\n")
image_downloader.folder = folder
image_downloader.download(image_links)
print("\ndownloading finished.")
print("time took ", time.time() - start)
import requests
import threading
import uuid
folder = None
def download_image(url, index):
try:
with requests.get(url, timeout=10) as r:
filename = f"image_{uuid.uuid4().hex}"
with open(f"{folder}/{filename}.jpg", "wb") as f:
f.write(r.content)
print(f"image{index} downloaded......")
except:
pass
def initialize_threads(urls):
threads = []
index = 1
for url in urls:
t = threading.Thread(target=download_image, args=(url, index))
index += 1
threads.append(t)
for thread in threads:
thread.start()
for thread in threads:
thread.join()
def download(urls):
initialize_threads(urls)